请不要把任何和邀请码有关的内容发到 NAS 节点。
邀请码相关的内容请使用 /go/in 节点。
如果没有发送到 /go/in,那么会被移动到 /go/pointless 同时账号会被降权。如果持续触发这样的移动,会导致账号被禁用。
邀请码相关的内容请使用 /go/in 节点。
如果没有发送到 /go/in,那么会被移动到 /go/pointless 同时账号会被降权。如果持续触发这样的移动,会导致账号被禁用。

这是一个创建于 924 天前的主题,其中的信息可能已经有所发展或是发生改变。
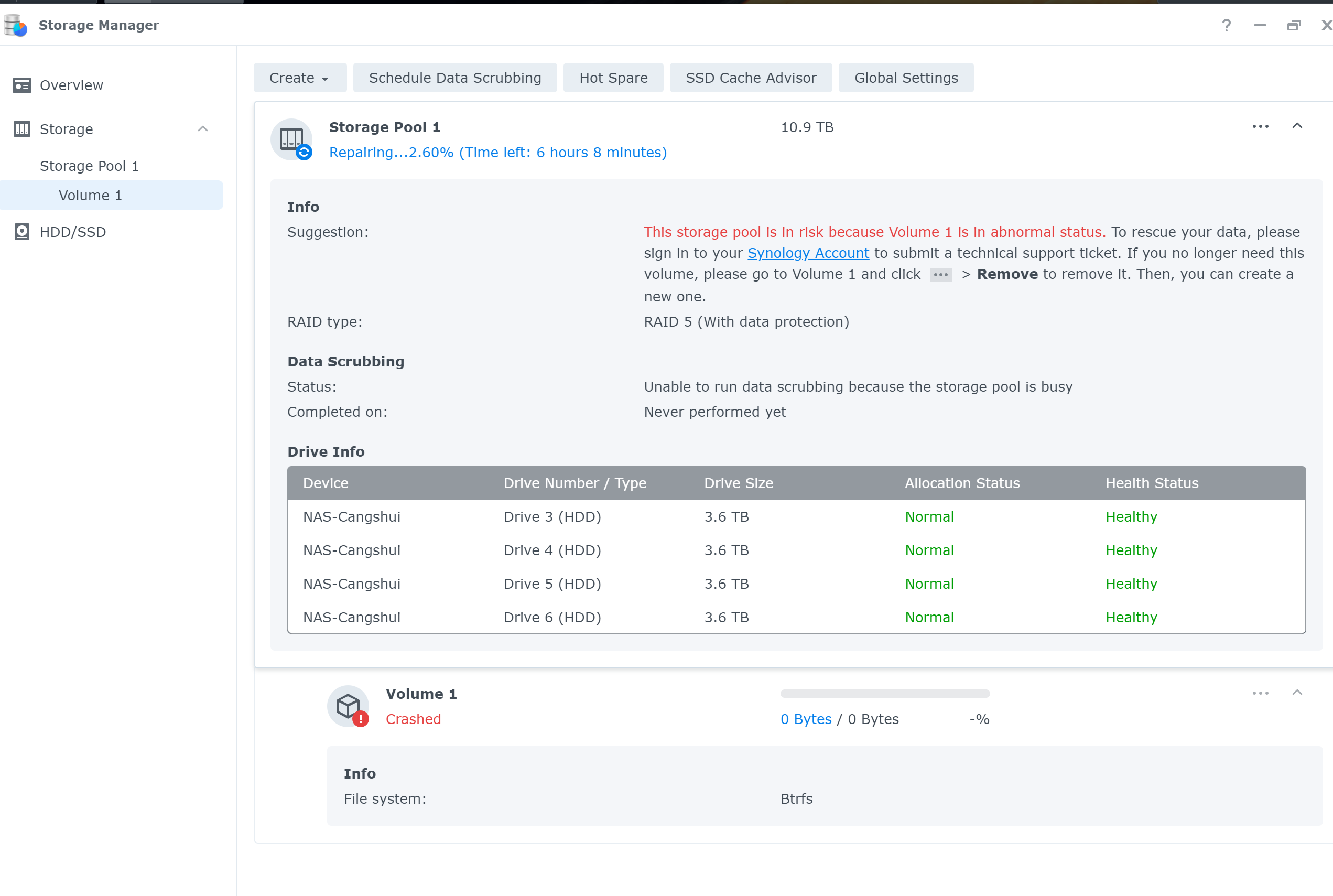
显示群晖四个盘都正常,也可以点击在线修复,但是 pool 提示损毁,连只读模式都没有,直接寄了
第 1 条附言 · 2023-03-09 07:21:08 +08:00
凉凉 修复完成之后存储池依旧是损毁的
 |
1
WebKit 2023-03-08 23:52:57 +08:00 via Android
点旁边三个点,看看有没有强行读写的选项,原来做一个硬盘也提示损毁,然后打开速写选项后啥事也没有
|

 |
3
gux928 2023-03-09 07:41:14 +08:00 via iPhone
raid5 都是直接寄么?
|
 |
4
kokutou 2023-03-09 08:13:16 +08:00 via Android
断过电吧。。
|
5
UXha45veSNpWCwZR 2023-03-09 08:14:41 +08:00 via iPhone
我读书少,raid5 不是有数据备份吗?怎么会无法恢复呢?
|
 |
8
bingkxChen 2023-03-09 08:19:40 +08:00
我只用 basic 和 raid1
|
 |
9
mikewang 2023-03-09 08:29:39 +08:00 via iPhone
对于 raid5 我有个疑问,假设四个盘都是好的,磁盘 1,2,3 校验值算出来和 4 不一致,那么应该听谁的?这种情况是不是无法纠错
|
 |
10
KeoC 2023-03-09 08:30:52 +08:00
用的啥硬盘?之前干过什么?
|
|
11
mikewang 2023-03-09 08:33:40 +08:00 via iPhone
如果坏掉一个,或者故意替换一个盘为新的去重建,那么肯定是依据剩余的三个盘重建,这个好理解
|
 |
12
testver 2023-03-09 08:40:11 +08:00
|
 |
13
dode 2023-03-09 08:41:48 +08:00
重新安装一套系统导入数据
每个硬盘单独接软件看看信息 用 truenas scale 吧 |
 |
14
neroxps 2023-03-09 08:42:54 +08:00
校验型阵列,能不碰就不碰。
|
15
UXha45veSNpWCwZR 2023-03-09 08:44:05 +08:00 via iPhone
所以到底是哪块硬盘坏了?是坏一块还是两块?
|
 |
16
qingmuhy0 2023-03-09 09:04:15 +08:00 via iPhone
@mikewang 如果只是坏一块是可以区分的,海明码的冗余度可以纠正“一位错误”,识别出“两位”的错误。除非坏了三块盘,否则是不存在你说的无法区分的情况的,具体数学原理我学业不精也没整明白,但最近在准备考试,海明码的如何使用还是写了不少…
如果只是坏了一块是可以和坏了三块区分的。 原理暂时没整明白,但“一位”可以纠正,“二位”可以识别,三位及以上检测不出来会和 0 位错混淆。 |
 |
17
Mithril 2023-03-09 09:07:31 +08:00 所以大家一直都不推荐搞 RAID5 。。。
|
 |
18
ltkun 2023-03-09 09:09:22 +08:00 via Android
群晖这种傻瓜化的 nas 慎用 试试 zfs 的 raid6 或许 7 吧 你会发现一片新天地
|
 |
19
versun 2023-03-09 09:12:40 +08:00 raid5 对于个人 nas 来说真的不安全,我一直都是 basic+实时备份到 OneDrive ,断电过几次,没出问题,比 raid5 稳定多了。。。
|
 |
21
lyhapple 2023-03-09 09:27:06 +08:00
这么巧, 我昨晚也是 ,淦,也不知道里面的数据挂掉没, 我做了 RAID1
|
 |
22
teasick 2023-03-09 09:30:53 +08:00
只用 basic ,然后重要资料定期备份到其他盘+其他 nas
|
 |
23
cpstar 2023-03-09 09:34:46 +08:00
跟 RAID5 关系不大吧。
这种 NAS 底层上了 RAID5 之类的,还会在软件层继续开软 RAID 。比如 QNAP 甭管下边是什么,还会构建 linux 层的 RAID 和 lvm |
 |
24
vmebeh 2023-03-09 09:36:44 +08:00 via iPhone
内存有 ecc 吗,也许是内存错误导致的
|
|
25
qingmuhy0 2023-03-09 09:37:45 +08:00
@qingmuhy0 emmm ,我想想总感觉我说的也有问题,坏 1 块和坏 3 块如何区分这个问题。。。我也搞不清了,还是以其他大神的科普为准吧。
|
 |
26
cue 2023-03-09 09:37:54 +08:00
重启一下就行了。
|
 |
27
sinboy1988 2023-03-09 10:19:27 +08:00
livecd 进去 fsck
|
 |
28
zhzy 2023-03-09 10:24:25 +08:00 家用真别 RAID, 重要数据跑个 rsync 定时任务靠谱得多, RAID 重建太容易爆炸了, 真要用 RAID 搞个移动硬盘做个冷备也行
|
 |
29
Ericality 2023-03-09 10:33:40 +08:00 喜闻乐见 终于遇到一个新鲜的例子来支撑 个人没事不要做 raid raid 不能保护数据 应该备份 这样的观点了
帮忙搜索了一下 可以参考下 https://www.ucmadscientist.com/almost-lost-it-all-again/ 当然这个教程极大概率和你遇到的问题不相同 但是可以试一下排查思路 去看看日志 看能不能导出数据 然后重置吧 此外 如果无法导出(注意是真的没有办法 因为越折腾数据越危险) 可以把硬盘单独卸下来 参照这个用 linux 尝试恢复 https://kb.synology.cn/zh-cn/DSM/tutorial/How_can_I_recover_data_from_my_DiskStation_using_a_PC |
 |
30
jklove123bai 2023-03-09 10:47:28 +08:00 raid5 貌似很早就被人淘汰了
|
 |
31
Scarletlens 2023-03-09 10:47:34 +08:00 建议用 basic ,多块盘之间通过内网 webdav 进行同步重要数据
|
 |
32
hjh142857 2023-03-09 10:54:07 +08:00
重要数据 raid1 或 basic+多盘同步,raid5 恢复太慢了
|
 |
34
lvcnsc 2023-03-09 11:35:54 +08:00
想发个图好难搞,链接凑合看吧
https://lvcnsc7-my.sharepoint.com/:i:/g/personal/lvcnsc_lvcnsc7_onmicrosoft_com/EaDQY5TahD9FtqrWuIIl0lkBnjgXrdWfcU_z--p-c3BUKQ 黑群晖,某天想把电源插到 ups 上去,不想关机等几分钟干脆直接拔了,就成这样了。。。 无法访问系统分区那两块盘读写啥的都正常,已损毁那块应该是没法读写的,不过它和另一块 HDD 是 RAID1 ,所以感觉不出来,唯一一块能正常访问系统分区的是上古 MLC 盘,因为寿命悠长所以平时在存监控视频读写 那块显示已损毁的盘在群晖系统依然能读取温度 smart 啥的,拿出来装硬盘盒格式化之后一切正常....估计塞回去继续组 raid1 问题不大,不过还是趁这个机会把两块 HDD 下岗换成了 SSD ,安静不少 |
 |
35
Bao3C 2023-03-09 11:40:26 +08:00
@Scarletlens #31 需要这么复杂吗,我直接用自带的 hyper backup ,定期从一个 basic 备份到另一个 basic
|
 |
36
a8500830 2023-03-09 11:54:18 +08:00
@versun 用 rclone 备份到 onedrive 吗。线程有没有要求,我测了一次 aliyundrive 号直接被封了。实时备份用的哪个命令。。
|
 |
38
justNoBody 2023-03-09 16:50:09 +08:00
换 unraid 吧,也别用 raid 了,直接拷贝反而靠谱一些,至少损坏了自己恢复起来更容易,重要数据再定期做个冷备份
|

|
41
versun 2023-03-09 20:59:07 +08:00 via iPhone
@a8500830 国内的云盘都没办法实时同步,只能定时运行任务,亲测 onedrive 和 dropbox 可以实时
|
|
42
versun 2023-03-09 21:00:35 +08:00 via iPhone
如果自建 nas 的话,我只相信 freenas 的 zfs ,搭配 ecc 内存
|
 |
43
liangddyy 2023-03-09 21:02:59 +08:00
看了评论有点吓人。我目前用的 SHR2 ,不知道安不安全。
|
 |
44
yanqiyu 2023-03-09 21:05:41 +08:00
先找个 Linux 机器看看啥情况?
|
 |
45
gdfsjunjun 2023-03-09 21:09:21 +08:00
所以我拿闲置电脑装个 Windows Server 算了,免得坑太多。就算系统挂了,找电脑接上也能读硬盘。
|
 |
46
rekulas 2023-03-09 21:34:41 +08:00
我之前 shr 在坏一个盘莫名其妙的损毁之后就改成 raid6 了,虽然空间小了点但安心了些,不过最重要的还是备份
|
 |
47
busier 2023-03-09 21:46:50 +08:00
存储服务器有什么瞎折腾!家用 NAS 虽然有个简易界面配置磁盘,但是鬼 TM 整天把磁盘配置改来改去的~!
我就直接跑 Debian 做存储服务器,文件系统用 btrfs + 自带快照!为防止暴毙,定时 rsync 同步到另一块硬盘! |
 |
48
tolbkni 2023-03-09 21:55:54 +08:00
BTRFS 的 RAID5/6 一直都不推荐生产环境用,到目前还是不稳定的
|
 |
49
loveour 2023-03-09 22:29:46 +08:00
@Ericality RAID5 还是至少比 RAID0 可靠,个人认为比散存也好。然而单一的存储总是不可靠的,总之要备份。经常看到有人问,硬盘坏了,数据很重要怎么办,很重要怎么不备份呢?不管号称多么可靠,只存在一个地方,就可能出问题。非要说的话,某些网盘可靠性比自家随存个硬盘的可靠性高点。
|
 |
50
BeautifulSoap 2023-03-09 22:43:42 +08:00
又一位 raid5 勇士以自己的惨痛经历证明了 raid 这个词里“冗余阵列”的意思。。。。。
家用要么 raid1 ,要么就别组 raid 好了。我 NAS 里十几 T 的几个硬盘都是直接用的,真正少见重要的东西定期用 rclone 往其他硬盘,和多个云存储上备份。就算真硬盘炸了一块,那些资源也不是稀有玩意,没多大损失 |
 |
51
yaoyao1128 2023-03-09 22:54:51 +08:00 via iPhone
其实存在很大的一个问题是文件系统……
btrfs 说明了 There are some implementation and design deficiencies that make it unreliable for some corner cases and the feature should not be used in production, only for evaluation or testing https://btrfs.readthedocs.io/en/latest/btrfs-man5.html#raid56-status-and-recommended-practices 以及……你的硬盘 smart 是直通的 sata 控制器吗……还是 usb 转的那种控制器? |
 |
52
sadan9 2023-03-09 23:15:07 +08:00
SHR 本质上是 mdadm + lvm 。
ssh 上去 mdadm -D /dev/md0(1,2,3,4,5) 的结果贴出来看看。 理论上 md0 和 md1 应该是系统区。md2 开始以后是数据。 |
 |
53
qbqbqbqb 2023-03-09 23:57:36 +08:00
@qingmuhy0 RAID5 用的奇偶校验码不是海明码。
海明码需要的校验位更多,比如 4bit 数据位+3bit 校验位,这样才能提供足够的码距来实现“纠一位错、检二位错”,对应到磁盘阵列上是已经淘汰的 RAID2 模式,用 7 块盘,只有 4 块盘的可用空间,利用率很低,现在已经没有产品支持这种阵列了。 RAID5 阵列,用 n+1 块盘,n 块盘可用空间,只能“检一位错”。 |
 |
55
iseki 2023-03-10 00:19:18 +08:00
我记得之前看到过讨论,RAID5 这种模式因为 URE 等等,可靠性其实是存疑的
|
 |
56
Cursor1st 2023-03-10 08:45:16 +08:00
https://www.yuque.com/cursor/kb/wcs3c2
我是采取单盘 Basic ,之前可能因为用了 SSD 缓存,导致掉盘了,一通查找操作,最后算是保留数据后恢复了,记录给你看看,不知道有没有参考性。现在我是不用 SSD 缓存了😂 |
 |
57
bg7lgb 2023-03-10 09:02:02 +08:00
raid1 也不做了, 直接 Basic ,然后 HyperBackup 到另外一块硬盘上。
|
|
58
Ericality 2023-03-10 09:50:57 +08:00
@loveour 是的 raid5 比 raid0 可靠
可能是我没表述清楚 我想说的是 组 raid1/raid5/raid6 就认为数据万事大吉 不需要备份的情况 其中除了 raid1 稍微好一点以外 剩下的根本无法替代定期备份 以及网盘的可靠性是比自己搞要高得多 这毋庸置疑 但是一方面本地速度访问还是要快一些(至少在网络环境比较糟糕的地方) 另一方面数据存在本地还是多一层隐私的 只能说和云盘比起来各有优劣吧 hhh |
 |
59
jacyl4 2023-03-10 09:59:32 +08:00
提示损毁之后不要第一时间修复。直接重启,经历一个硬盘识别过程,再修。
|
 |
60
Titzanyic 2023-03-10 10:13:51 +08:00
家用的场景,感觉 raid 意义不大, 不如留出一个盘,使用自带的 Hyper Backup 通过 USB 做循环备份或者异地网络备份到另外一台 NAS 。
|
 |
61
SgtPepper 2023-03-10 10:35:43 +08:00
家用 nas 憋整 raid 案例+1
|
 |
62
Huelse 2023-03-10 11:12:10 +08:00
自己的 nas 就不要用 raid 了,直接单盘用,重要文件多个盘之间 rsync 即可
|
|
63
Scarletlens 2023-03-10 11:37:46 +08:00
@Bao3C 不复杂的,这个是实时,也不是群晖的压缩格式,方便查阅,相比 hyper backup
|
 |
64
YongXMan 2023-03-10 12:31:06 +08:00
这帖子有毒,看了这个帖子后,当天晚上自己的黑裙也掉盘了,查看日志是 ESXI 上也有存储池掉盘的日志,只不过 ESXI 日志里显示的是其他的存储池,这个盘在跑 PCDN ,给群晖的存储池都是直通的,做了硬 RAID5 ,故障时间点和日志能对上。重启了一些 DSM ,盘的状态恢复了。
ESXI 7.0 下稳定运行了 1 年了,没有发生过类似的情况,刚才先把 ESXI 升级到了 8.0 ,再观察观察,估计是有的盘快到寿命了。 虽然做了 RAID5 ,但是重要数据还是单独开了一块盘,每周 rsync 备份。 |
 |
65
ducks 2023-03-10 14:22:25 +08:00
我主力机数据是 123 备份的,每晚复制一份到移动硬盘,再推一份到云存储(循环 推的时候自动删除 7 天前的备份),移动硬盘就普通的,机器也是 7*24 小时跑的,11 年丢过数据,怕了怕了
|
 |
66
ryd994 2023-03-10 16:21:35 +08:00 via Android @mikewang #9 对的
raid 的设计前提是假设磁盘坏就是彻底失效。raid 无法解决冷错误问题。zfs 有 checksum ,所以可以。 @testver #12 不仅如此,单盘越大也越不安全。基本上 3tb 以上就不建议用 raid5 而至少应该 raid6 @qingmuhy0 #16 首先,raid5 用的不是海明码,raid2 才是 raid5 本身没有 checksum ,部分实现有,比如 zfs 其次,注意你说的情况和#9 说的不同,这种情况下 raid5 确实有足够的信息去检测到不一致,但无法知道是哪个盘不一致,因此也就无法踢出这个盘重建。 zfs 可以是因为 checksum 可以指出是哪个盘有错误。这样剩余的盘有足够的信息重建。 从实现上来说,raid 的目标是高性能高可用,而不是数据保全。一般的 raid 实现不会在读取时校验数据。类似的,对于 raid1 ,如果两盘数据不一致,raid 标准并没有规定要返回哪个版本。返回任何一个都不违反协议设计。 @Ericality raid1 一样完蛋,raid1 只有 1 位冗余,最坏情况下和 raid5 是一个水平。 raid1 一样有数据不一致问题。一样有单盘重建时间的问题。raid6 有 2 位冗余,因此理论上可以纠正 1 位错误(实际上没有实现),或者恢复 2 位数据。 大单盘的重建时间是以天计的。所以重建过程中再损坏一块的可能性很大。raid1 重建完全依赖于镜像盘,因此同样无法幸免。 2 位冗余意味着只要你不是重建时连坏三块,数据就还有救。 |
|
67
ryd994 2023-03-10 16:27:21 +08:00 via Android 生产中不用 raid5/6 而用 raid10 的原因是服务器需要随机读写。raid5/6 随机写入需要读取整个条带所有盘上的数据,修改再回写。raid1 只需要修改镜像盘上的数据即可。
个人文件服务器不存在这个问题。又不是跑下载。smb 文件共享都是大文件。而且瓶颈通常是网络而不是磁盘性能。因此个人服务器用 raidz2 才是正解。 同样 4 盘,组 raid10 还是 raidz2 ,容量都是一样。 raidz2 可以损失任意 2 盘,而 raid10 不能,要看运气,看失去的哪 2 盘。 |
|
68
qingmuhy0 2023-03-10 22:31:21 +08:00
@ryd994 能劳烦指点一下,如果对相对专业(或者说全面的系统的了解)的数据安全(物理层面的保护,可以不包括阻止未经授权访问之类的安全分支,因为感觉和这个问题不是一个分支,当然如果一起的书籍或者课程俺也有业余时间去了解,尽量能从数学层面解释清楚的。)知识比较感兴趣,有什么系统的课程或者着书籍教程介绍之类的嘛,还是说最好的办法是看各个文件系统的说明文档。
个人兴趣使然,非本人专业领域。 |
|
69
ryd994 2023-03-10 22:54:22 +08:00 via Android
@qingmuhy0 我也不是专业人士。关于 raid 的结构,维基百科解释的很清楚。关于 raid5 的缺点,特别是为什么不能用于大容量阵列,网上相关的信息也相当多。
|
|
71
loveour 2023-03-13 21:57:54 +08:00
@Ericality 没错,作为个人用户来说,永远别指望有什么特别保险的存储方式,一定得多备份。网盘也不一定可靠。自己线下的备份也还是要有的。
|
 |
72
justaname 2023-03-23 23:07:23 +08:00 群晖的 raid5 实际上是 mdadm+LVM+ext4/btrfs ,你的配置应该是 btrfs ,而 btrfs 这玩意儿配合硬 /软 raid 非常容易挂掉,猜测是因为 CoW 机制导致的 metadata 和 superblock 容易出现一致性问题。建议是 raid5/6 上面就老老实实上 ext4 ,如果希望使用先进的特性比如快照压缩啥的就用 zfs 或者用 btrfs 的 raid1 ( btrfs 的 raid5/6 依然不稳定,有 bug ,别用)。
说到底高级文件系统+底层 RAID 容易炸的原因基本上都是因为缓存不一致的问题,因为各种原因(断电 /内核崩溃)导致高级文件系统出现应该落盘而没落盘的元数据往往是灾难性的,这也是 mdadm 这种软阵列很难确保可靠性的原因,即使是带电池的硬卡也可能出现一些 corner case 导致意外断电后缓存上的数据在阵列再次上电之后没有顺利写入,只不过硬卡不太可能出现系统本身崩溃导致的缓存一致性失效(毕竟硬卡工作在更底层)。相对来说 ext4 这种就很难出现这种问题,最多就是损失一部分文件,不太会出现整个阵列挂掉的情况。 |
|
73
justaname 2023-03-23 23:42:25 +08:00 @ryd994 raid 重建本身出错的概率其实并不高,即使是大单盘。好点的硬卡或者软阵列重建基本上跑满单盘写入速度,14TB 也就一天不到的时间就重建好了。另外因为 raid 巡读的存在很少有平时正常巡读但是重建的时候突然挂掉的,就算有 rot bit 也很难导致整个阵列崩溃,最多丢部分文件文件。
真正出现一盘崩溃甚至所有盘都健康结果阵列突然崩溃的情况通常是我上面说的缓存不一致导致高级文件系统自身炸了。当然这种情况理论上依然可以通过人工分析文件系统找回大量数据,但是相对来说就复杂了很多,专业数据找回的价格也不便宜 最后还是得反复强调,btrfs over raid 是坑,别碰,要用 mdadm 或者 btrfs 就老老实实 ext4 或者 ntfs 这种特性简单的文件系统 |
|
74
justaname 2023-03-23 23:43:43 +08:00
@73 最后一句话应该是“要用 mdadm 或者 硬 raid 就老老实实 ext4 或者 ntfs 这种特性简单的文件系统”
|
 |
75
HarveyLiu 2023-03-30 21:33:09 +08:00
zfs ,表示各种情况都出现了,插入新硬盘,直接就恢复了,除了内存依赖比较大,没啥事。
|