
这是一个创建于 731 天前的主题,其中的信息可能已经有所发展或是发生改变。
想升级一下自己的电脑配置,跑下大模型玩一玩,我想用大模型做自己的个性化助手,有这方面经验的大佬吗,跑大模型在训练什么数据啊
 |
1
cloud2000 2023-11-20 19:42:13 +08:00 你问的很泛,所以很泛的答 2 句。
16gb 显存起步,才能跑稍微"像 gpt-3.5"的模型。准备好了就谷歌,到处都是资料。 |
 |
2
sarcomtdgzxz 2023-11-20 19:44:38 +08:00
智谱的模型 运行就 12g
|
 |
3
gorira 2023-11-20 19:46:18 +08:00
少爷先来一台 128G 的 M3max 吧
|
 |
4
cmos 2023-11-20 19:51:29 +08:00
“跑下大模型玩一玩”用 llama.cpp 就可以了,内存 32G 可以轻松跑起来 Q8 量化的 llama2 13B 版本,连 GPU 都不需要。
“跑大模型训练数据”,起码得 4 块 V100 和 256G 内存才能顺畅的调试。 想调试模型,可以参考我的服务器配置,自己组一个: 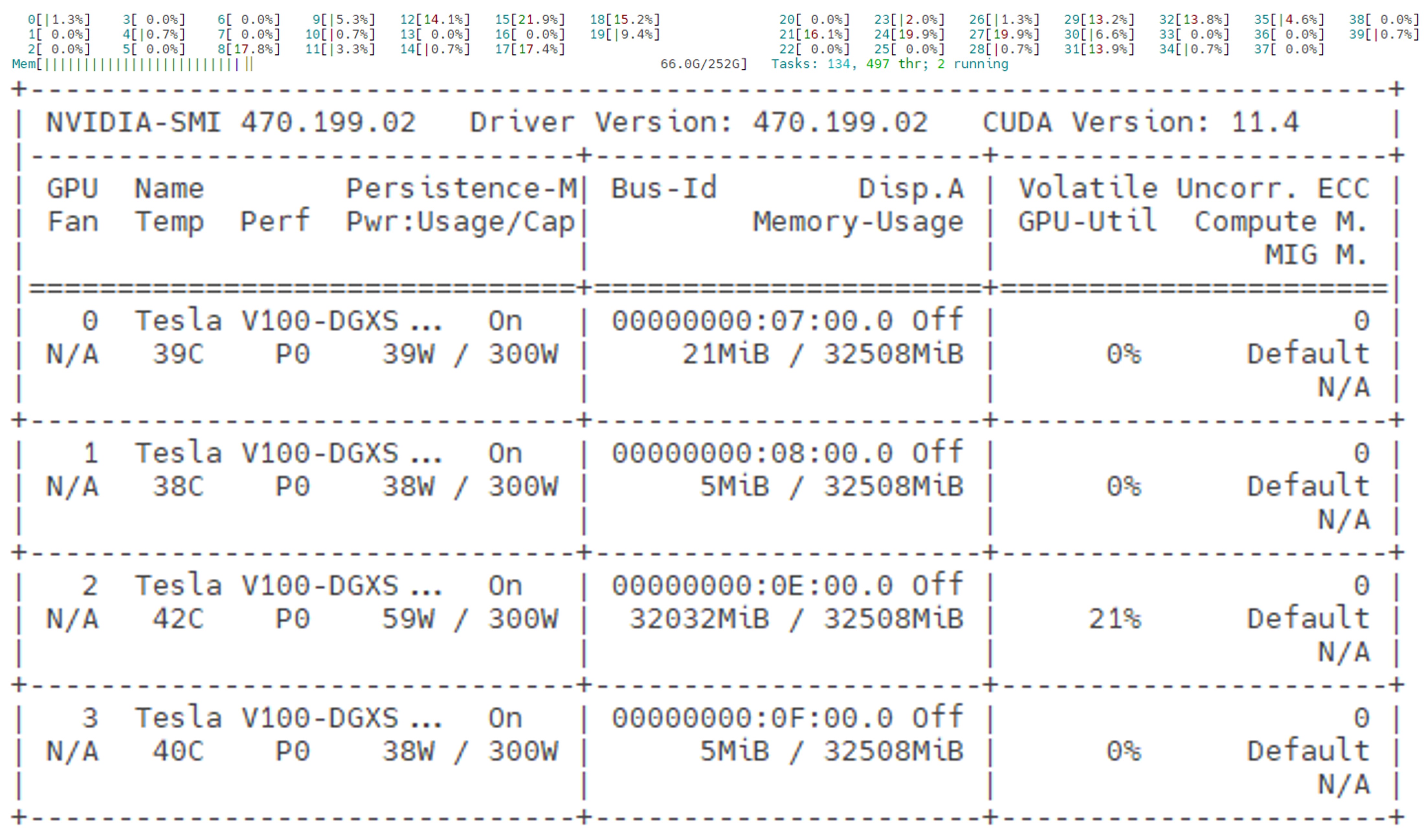 |
 |
5
ShadowPower 2023-11-20 19:55:13 +08:00 配置升级的选择:
预算低,无动手能力: 4060Ti / 2080 魔改 22GB 预算最低,有软件+硬件方面的动手能力: P40 24GB (性能不是很强,但显存带宽还不错,694.3 GB/s ) 高预算: 双 3090 (对主板/供电要求很高,还需要一个房间来放,因为很吵) 另类选择: 买一台 Mac Studio M2 Ultra 192GB 内存 只能玩 llama.cpp ,生态差了点,训练不行 |
|
6
ShadowPower 2023-11-20 19:59:45 +08:00
如果你的电脑有 8GB 以上的内存,我建议不升级
先用 llama.cpp 玩一下 4bit 量化的模型 如果觉得 llama.cpp 用起来麻烦,用这个: https://github.com/LostRuins/koboldcpp 或者这个: https://lmstudio.ai/ |
 |
8
suqiuluck OP @ShadowPower 了解了,感谢大佬回复
|
 |
9
Mark24 2023-11-20 20:35:17 +08:00
钱包不允许
|
 |
10
NoOneNoBody 2023-11-20 20:45:53 +08:00
站内有人发过用自己的聊天记录训练的(年初的帖子,全文在其 blog ),你可以参考一下
要玩训练模型我是耗不起,基本看前几段就劝退我了,还是继续玩我的小模型好了 |
 |
11
Rnreck 2023-11-20 22:15:36 +08:00
@NoOneNoBody #10 有链接吗,去看看
|
|
12
NoOneNoBody 2023-11-20 22:23:31 +08:00 |
 |
14
kuanat 2023-11-20 22:52:10 +08:00
硬件选择楼上已经说了,显存要够大才能跑大模型。
如果你在生产机器之外需要一个开发验证平台,现在 4060 移动版的笔记本非常合适。相对台式显卡溢价低,8GB 对于验证程序来说够用了。关键是 40 系的能效比很高,而且价格非常卷。 |
 |
15
cwyalpha 2023-11-20 23:16:44 +08:00 via iPhone
4060ti 16g 双卡可以用来训练或者推理麽?
|
 |
16
CaptainD 2023-11-21 14:35:37 +08:00
我用 3060ti 8g 去跑 LLAMA2 7b ,只能设置精度为 8bit ,而且推理速度很慢
|
 |
17
leipengcheng 2023-11-21 17:45:38 +08:00
我之前用 4060 的游戏本跑过,后面感觉还不如直接用 gpt 呢。。。
|
 |
18
shuiguomayi 2023-12-15 22:23:41 +08:00
@kuanat GeForce RTX 4060 显卡么? jd 上搜是 8G 显存. 请教下, 8G 能跑什么样的大模型?
|
|
19
kuanat 2023-12-15 23:22:13 +08:00
@shuiguomayi #18
是 RTX 4060 Mobile ,笔记本上用的,8GB 显存。说的是开发验证这种需求,你需要训练一个模型,先在本地写个小规模的验证程序,然后放到服务器上去跑大数据集。并不是常见的用模型来推理,推理这个需求还是 12GB 起步吧,8GB 只能跑一些简化或者降低精度的模型,速度也不太理想。 每一代 60 显卡都会有个显存略大的版本,可以理解为 nvidia 推广 cuda 生态用的,因为这个级别上加显存对游戏性能几乎没什么影响。说移动版 4060 是因为它相对 3060 加了显存,而且能耗比很好,市面上的笔记本能做到 5000 块,比起台式机性价比可以的。 |
 |
20
xbird 2023-12-19 05:14:16 +08:00
我本来也觉得部署大模型需要大显存,得上 M3 Max ,但实际上如果只是运行(也就是推理),不训练,部署自己用的,内存够大就行了,64gb ,128gb ,内存很便宜,不需要 gpu ,cpu 就够了,速度也慢不了多少。
Lm studio 自己下个试试就知道了。 我发现中文资料很少。 希望对你有帮助。 |