 |
MoearV2EX 第 611813 号会员,加入于 2023-01-31 15:58:21 +08:00今日活跃度排名 10071 |
| 写了个 I 站批量下载的 GUI 小工具,单作者/播放列表全搬运 分享创造 • Moear • 1 小时 40 分钟前 • 最后回复来自 yeqizhang | 1 |
| 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! 分享创造 • Moear • 2025 年 12 月 18 日 • 最后回复来自 Moear | 28 |
| 为了优雅地斗图,我花 2 小时写了一个「恶俗企鹅 / 高雅人士」表情包生成器 分享创造 • Moear • 2025 年 12 月 2 日 • 最后回复来自 klo424 | 10 |
Moear 最近回复了
2025 年 12 月 18 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@Hansah cosyvoice 最长大概 20s 左右吧 单句过长了会自动截断分成若干个任务,然后分开跑,当然你也可以自行截断(在文本编辑页面换行 然后丢到计划任务里面去), 程序在最后提供了 FFmpeg 一键合成音频的方式,此时从理论上来说无限长度 控制符可以看一下 23 楼的那个回答
2025 年 12 月 18 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@Hansah 那玩意阿里巴巴没开源😭只开源了 0.5b 参数量的版本
2025 年 12 月 17 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@MindMindMax 苹果大带宽的内存跑 ai 啥的还是挺香的😂
2025 年 12 月 17 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@shuxge1223 理论来说用精细控制模式可以做到 但我没咋用过这个精细控制模式
需要额外打标的,标签可以在 https://github.com/FunAudioLLM/CosyVoice/blob/a7d6e2251adb64f7cef595c5c71c5763cb1d162b/cosyvoice/tokenizer/tokenizer.py 里面找到,不过我目前就做了几个简单的打标快捷键,其他的 cosyvoice3 新增的暂时还没拉上来😂
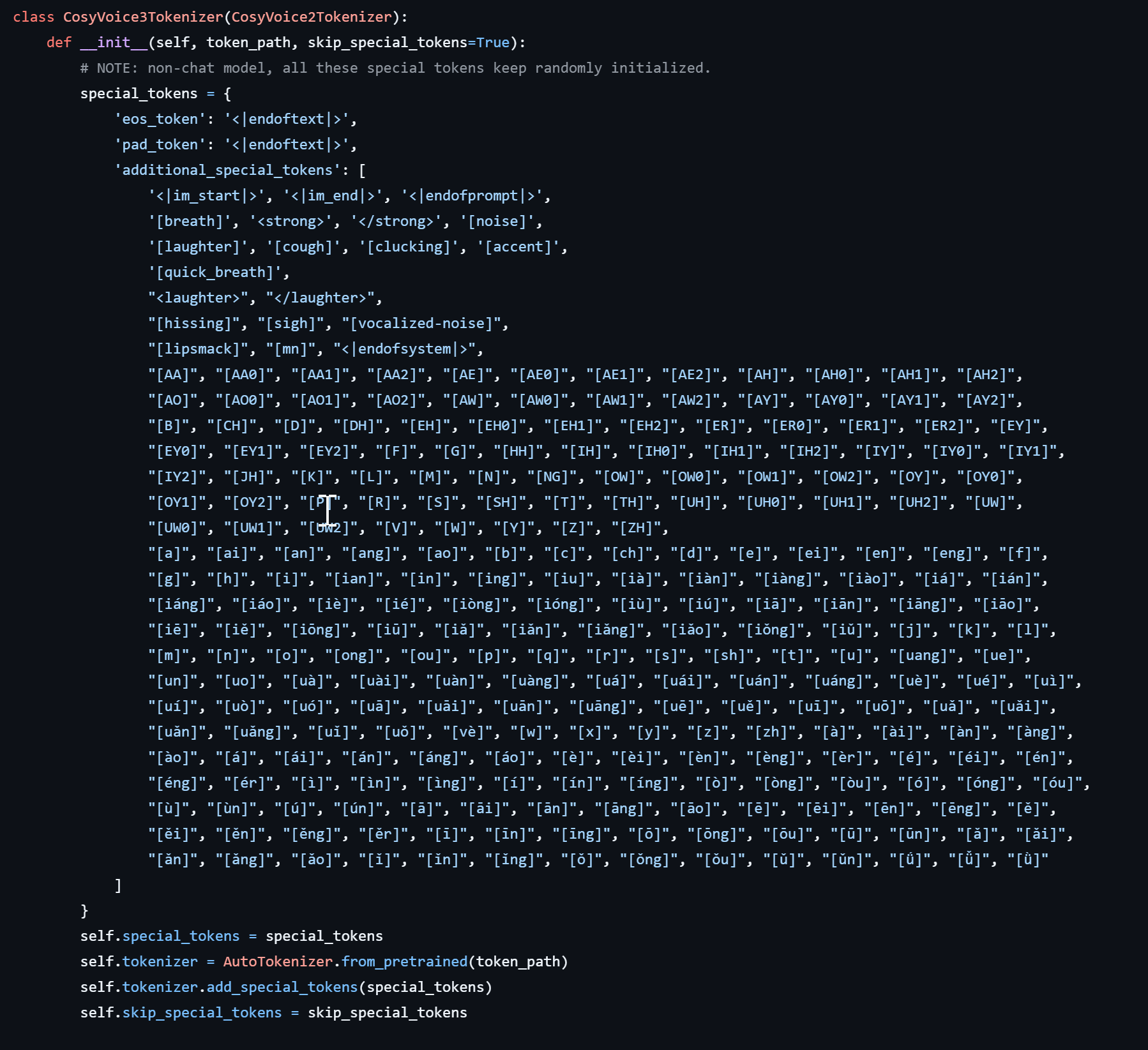



需要额外打标的,标签可以在 https://github.com/FunAudioLLM/CosyVoice/blob/a7d6e2251adb64f7cef595c5c71c5763cb1d162b/cosyvoice/tokenizer/tokenizer.py 里面找到,不过我目前就做了几个简单的打标快捷键,其他的 cosyvoice3 新增的暂时还没拉上来😂




2025 年 12 月 17 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@MindMindMax 我自己的显卡是 4070m(笔记本 当做 4060ti 8gb 版本就行了) rtf(Real-Time Factor ,实时因子)大致在 0.8~1.6(越低越好 说明推理数值越快 rtf 是 1 的话就说明显卡花 1s 的算力可以推理出 1s 的音频来) 纯靠 cpu 的话我用 q1hy(13900hk es)的 rtf 大概是 10,30s 时间能推理出 3s 的音频来
2025 年 12 月 17 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@Xhack 可以自行找一段 Moss 的 3s 到 10s 的无底噪的音频截取下来,来源可以是在 b 站搜一下[ [流浪地球①] MOSS/550W 语录/语音集 (自存)] 作为参考音频推理使用 现在的 tts 模型基本都支持了这种无训练方式复刻音色的功能了
2025 年 12 月 17 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
2025 年 12 月 16 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@Bantes 仁者见仁智者见智 可能是你对 tts 不感兴趣吧
2025 年 12 月 16 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@Frankcox 不知道 建议问问别人 gptsovits 没咋用过
2025 年 12 月 16 日 回复了 Moear 创建的主题 › 分享创造 › 阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用! |
@noming 零样本复刻模式/修复模式下必须要填参考文本+参考音频(参考文本一定得是参考音频的完整文字部分) 指令模式/精细控制下必须要填参考音频