目前已实现的功能:
- 通过上传文件 GPT embedding
- 通过输入网页 URL 进行 GPT embedding
- 创建 vector 数据,后续可以多次使用
- 直接使用他人创建好的 vector 数据
- 100% 代码开源
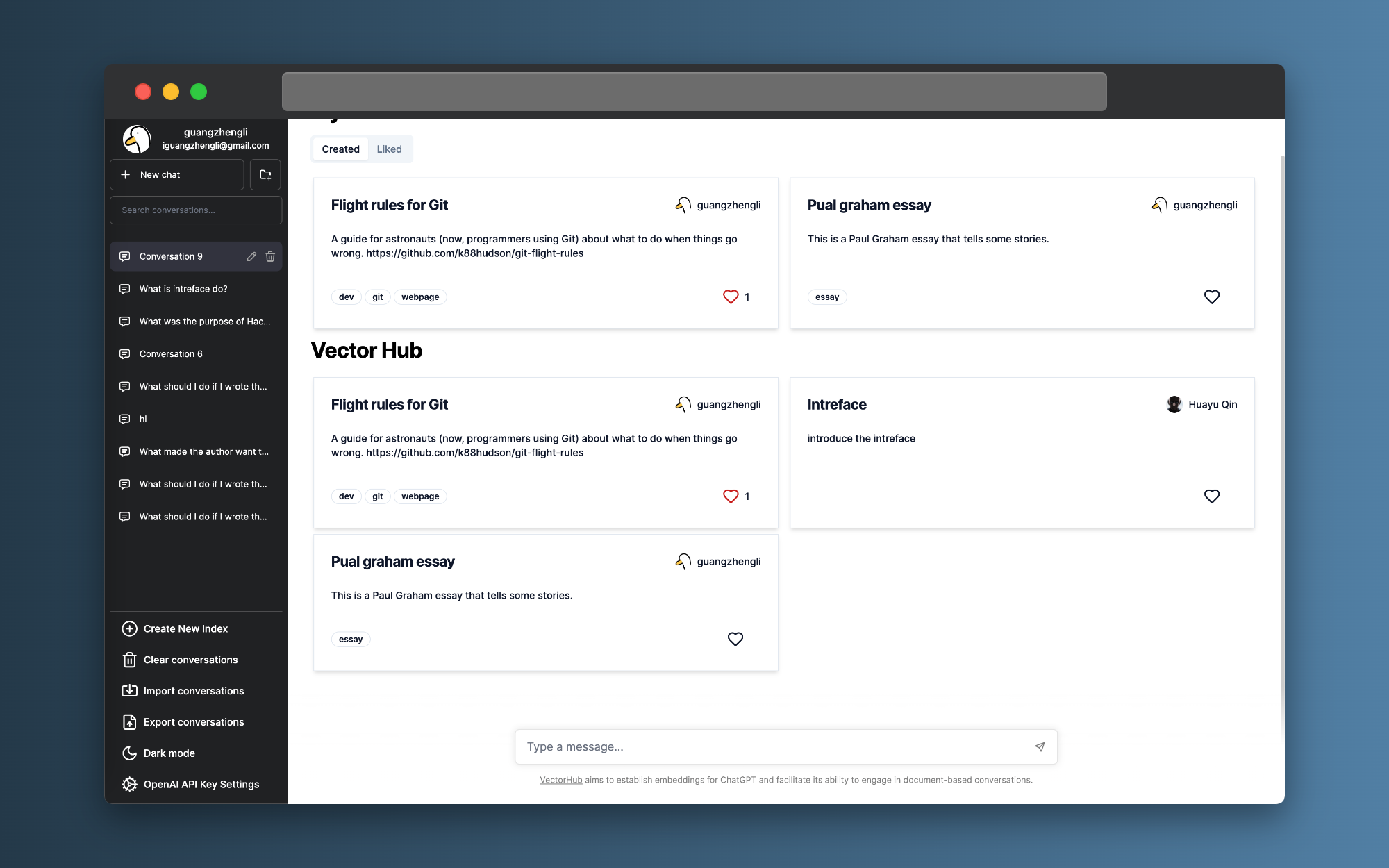
我在今年四月的时候,开源了 ChatFile 项目,收获了 2.4K 的 stars, 该项目的目的是上传文件进行 GPT 的 Embedding ,能够上传 PDF 、Epub 、Markdown 、Text 、Zip 等等一些系列格式的文件做到 ChatPDF 之类的效果。
新的项目设计的初衷是,ChatFiles 在之前开源后,收到了很多用户的上传文件使用 Embedding ,但是这些 Embedding 并不能被所有人重复使用,这样就形成了大量的浪费,大家都在给 OpenAI 交重复的钱💰。
例如我在 https://chat.vectorhub.org 中 Embedding 了 https://github.com/k88hudson/git-flight-rules/blob/master/README.md 的材料。
并提供了一些快速的开始问题,那么其它用户就不需要再次花钱 embedding 就可以使用该数据。
大家也可以想一想还有什么有趣的可以进行 embedding 的。可以用你的 API Key embedding 然后所有人一起使用。也可以在这个帖子讨论,后续项目的进展在 我的推特 上更新。
目前项目还在初期,大家可以多多提提 bug 。新的项目地址: https://github.com/guangzhengli/vectorhub