独立开发者节点
愿每一位独立开发者都能保持初心,获得一个好的结果.

 |
1
Sezxy 1 day ago
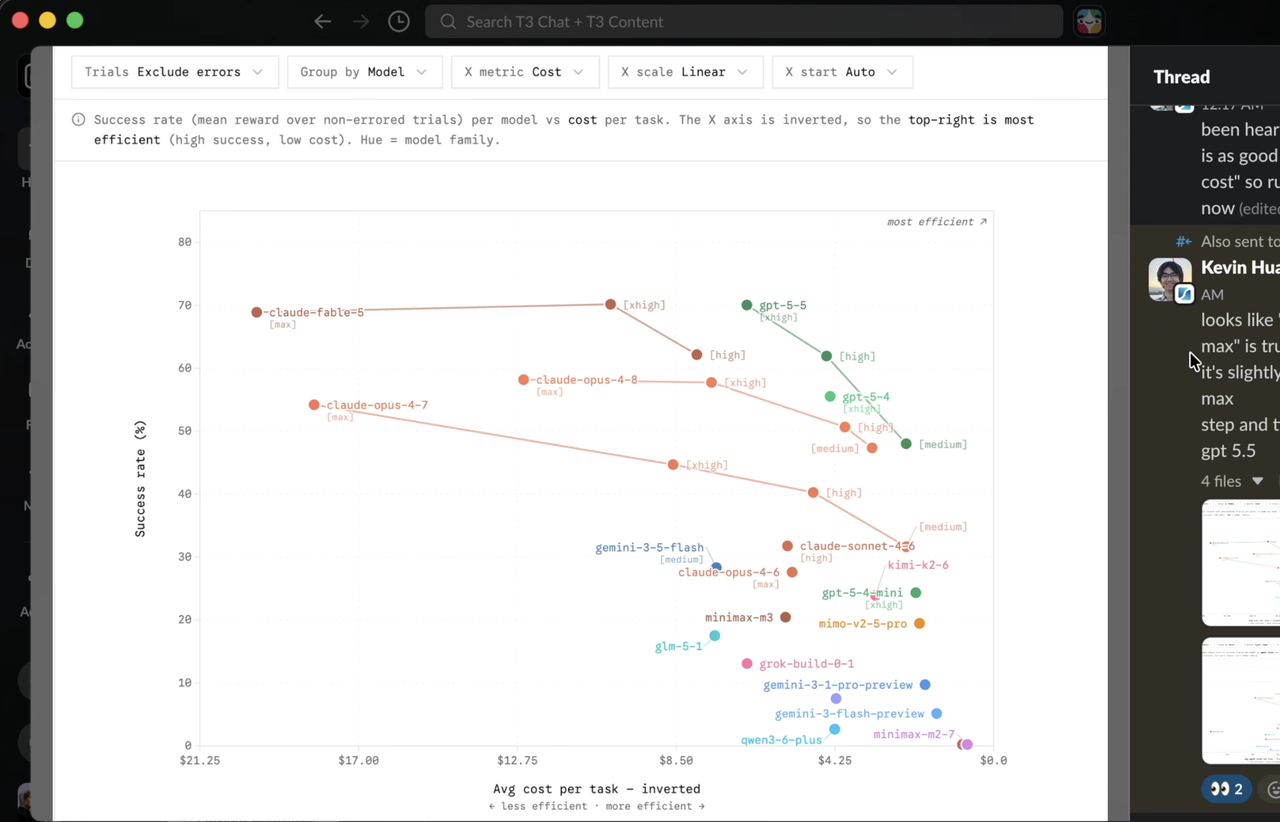
A÷: 检测到疑似蒸馏行为,降级到 4.8opus
|
 |
2
Tink PRO 这个模型道德限制太多了,根本没法用
|
 |
3
penisulaS 1 day ago
我感觉 5.4-mini 都够我用的
|
 |
4
photolife 18h 45m ago
让 gpt 拆解了一下::
技术拆解 1. Fable 与 Mythos 的关系 从 Theo 的描述看,架构关系大概是: Mythos 5 基础能力 ↓ 安全策略 / 路由 / 拒答 / prompt 修改 / steering / 微调限制 ↓ Fable 5 用户可访问版本 所以 Fable 不是“另一个弱模型”,而更像是: Mythos 能力 + 安全控制层 + 产品策略层 这会导致两个结果: 第一,普通 coding 任务里你能感受到接近 Mythos 的能力。 第二,一旦任务触碰敏感边界,评测和体验会突然变差。 2. 为什么它 coding 体验强? 从视频案例看,它的强不是单点能力,而是几个能力叠加: 能力 表现 大上下文工程理解 能读老项目、理解迁移目标 多步执行 能跑迁移、修错误、继续迭代 工程 taste API 、测试、文档、代码结构更像资深工程师 自我验证 会写 fuzzers 、测试、验证性能方案 模糊任务探索 能接受“看看有没有更高性能方案”这种宽泛指令 UI/3D/交互能力 能生成游戏、terminal UI 、多人 demo 真正的跃迁点不是“它会写一个函数”,而是它开始像一个能独立探索的工程代理。 3. 它仍然不可靠在哪里? A. 大迁移会产生功能损坏 Theo 的老项目迁移案例说明:模型可以把项目推进到“看起来很接近”,但核心功能可能坏掉,UI 也可能 regression 。 这意味着它适合做: 初始迁移草稿 大规模 refactor draft 快速 prototype 测试/验证 scaffold PR 初稿 但不适合无人监督地直接 merge 。 B. 它会“过度自信地误解系统” Lakebed 例子很典型:模型看到 main branch 与 package/prod 环境不一致,就判断系统坏了。但实际这是 staging/prod 的部署策略。 这类错误说明它虽然聪明,但仍可能误解: 分支策略 发布流程 环境映射 内部约定 组织特定上下文 解决方式是给它明确的 repo operating manual ,比如: # Deployment model - main branch deploys to staging - prod branch deploys to production - npm package release follows production promotion - staging-only fields are expected on main 4. 成本模型:强,但要控预算 Theo 的例子很清楚:usage-based 对高强度 agent workflow 可能非常危险。 适合的控制策略: 风险 控制方式 一次 workflow 烧太多钱 设置 hard budget / daily cap agent 无限迭代 限制 max turns / max tool calls 任务太大 拆成小 PR / 小 worktree 没有验收标准 先写测试,再让模型改 产物不可 merge 要求每轮输出 diff summary + test result 比较推荐的用法: 1. 让模型先审计,不改代码 2. 让模型提出 plan 3. 人确认 plan 的边界 4. 让模型建 worktree 实施 5. 强制跑 test/lint/typecheck 6. 让另一个模型 review 7. 人最后 merge 5. 安全层带来的产品问题 这期视频真正值得关注的是:Fable 的能力不是稳定常数,而是会被策略影响。 可能出现三种状态: 正常 Fable → 体验极强 透明 fallback 到 Opus → 用户知道模型换了 不透明削弱 → 用户以为还在用 Fable ,但能力被限制 第三种最危险,因为它影响: benchmark 公平性 用户信任 成本透明度 企业采购评估 高级研发场景 如果团队要评估这种模型,不能只看平均 benchmark ,而要记录: 实际是否 fallback 是否拒答 是否输出风格突然变保守 是否同一 prompt 多次结果波动 是否敏感领域性能异常下降 6. 数据留存:企业使用的硬门槛 Theo 提到 Fable 5 要求 30 天数据留存。这个点对企业很关键。 不适合直接送进去的内容包括: 客户源码 未公开产品路线图 安全漏洞细节 生产数据库 schema 私有日志 合规受限数据 受 NDA 约束的代码或文档 如果企业要用,比较安全的方式是: 只给: - synthetic repro - anonymized logs - public code - isolated branch - stripped-down schema - no secrets / no customer data 最实用的工程用法 用法 1:大型遗留项目现代化 适合给 Fable/Mythos 的任务: Read this repo and produce a migration plan from the current stack to X. Do not modify files yet. Identify: - risky modules - dependency blockers - test gaps - migration phases - smallest shippable PR sequence 不要一开始就说“把整个项目迁移到新栈”。那会烧钱,也容易产生不可 merge 的大 diff 。 用法 2:PR 清理工厂 Theo 这个用法很值得学: For each stale PR: 1. create a worktree 2. inspect the diff 3. rebase mentally against current main 4. decide: update / rewrite / close 5. produce a short recommendation 6. do not merge anything 这非常适合处理积压 PR 、老分支、半成品功能。 用法 3:AI first reviewer 让 AI 在人类 reviewer 之前做: diff summary risky files missing tests performance concerns security concerns screenshot/video checklist likely regression areas 这会把人类 review 从“找基础问题”升级为“判断产品和架构”。 用法 4:让模型写验证工具,而不只是写功能 Theo 最有价值的观察之一是:Fable/Mythos 会主动写 fuzzers 。 你可以直接要求: Before changing the implementation, write a small test harness or fuzzer that would catch regressions in this module. Then run it against the current implementation. Only after that, propose the change. 这比“直接修 bug”靠谱很多。 我的判断 这期视频的技术核心不是“Fable benchmark 又高了”,而是: AI coding model 正在从 autocomplete / pair programmer ,变成可以承担探索型工程任务的 semi-autonomous engineer 。 但它还不是完全 autonomous engineer 。它的边界主要在: 成本不可控; 安全策略不透明; 企业数据留存风险; 对项目内部上下文仍会误判; 大迁移容易生成不可 merge 的巨型 diff 。 最佳策略不是完全放手,而是把它放进一个受控工程系统: 小 worktree 清晰任务边界 先测试后修改 预算限制 AI review 人类最终 gate 这才是 Fable/Mythos 这类模型真正能落地的方式。 |