请不要把任何和邀请码有关的内容发到 NAS 节点。
邀请码相关的内容请使用 /go/in 节点。
如果没有发送到 /go/in,那么会被移动到 /go/pointless 同时账号会被降权。如果持续触发这样的移动,会导致账号被禁用。
邀请码相关的内容请使用 /go/in 节点。
如果没有发送到 /go/in,那么会被移动到 /go/pointless 同时账号会被降权。如果持续触发这样的移动,会导致账号被禁用。

这是一个创建于 656 天前的主题,其中的信息可能已经有所发展或是发生改变。
目录
深入解析绿联云 DX4600 Pro UGOS 系统 (2)
文章一些部分用词有点晦涩难懂,是因为有可能文章也会转载到别的平台,所以用了一些别名指代
比如:隧道 → 代理,内核 → C???h ,Meta → C????.meta
折腾这个 NAS 的系统,就像我以前学 coding 的时候看的那些教学书一样,《深入浅出》,有一种完全了解病根了才想得出对策的探索感。当然,我不希望一个正常的 NAS 系统需要用户自己探索这些。
接下来的教程全部都基于继续使用 UGOS 的前提下。出于各种各样的原因,更换系统的沉没成本已经大到无法接受,导致只能在不刷系统的情况下继续使用,那么以下教程想要教你部署的东西就是一台 NAS 业务能力基础中的基础,好坑都埋在基础之中。
这篇教程在介绍操作的时候都会讲解一下背后的大致原理,目的在于让所有入门者都知其然而知其所以然。只想无脑 copy-paste 命令跑通的伸手党用户大可去参阅其他人写的 pdf 教程,在绿联社区里有非常多,只需要回复一句“感谢楼主分享”即可获得。
目标
这个教程的目标只有 2 个:
- 搭建一个第三方媒体库
- 让公网也能访问它
于是,你以为要满足这个需求,平台弄成这样就好了:
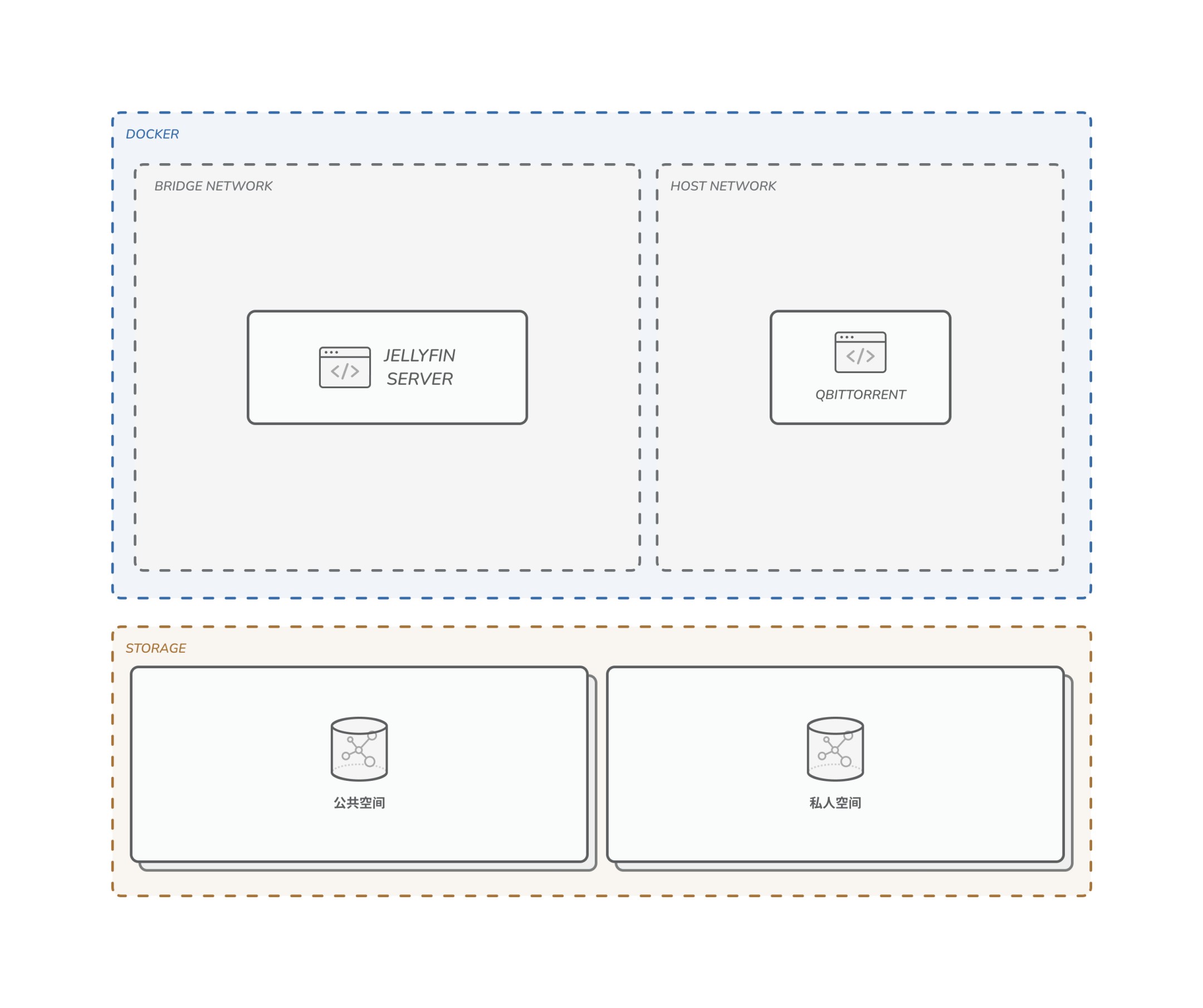
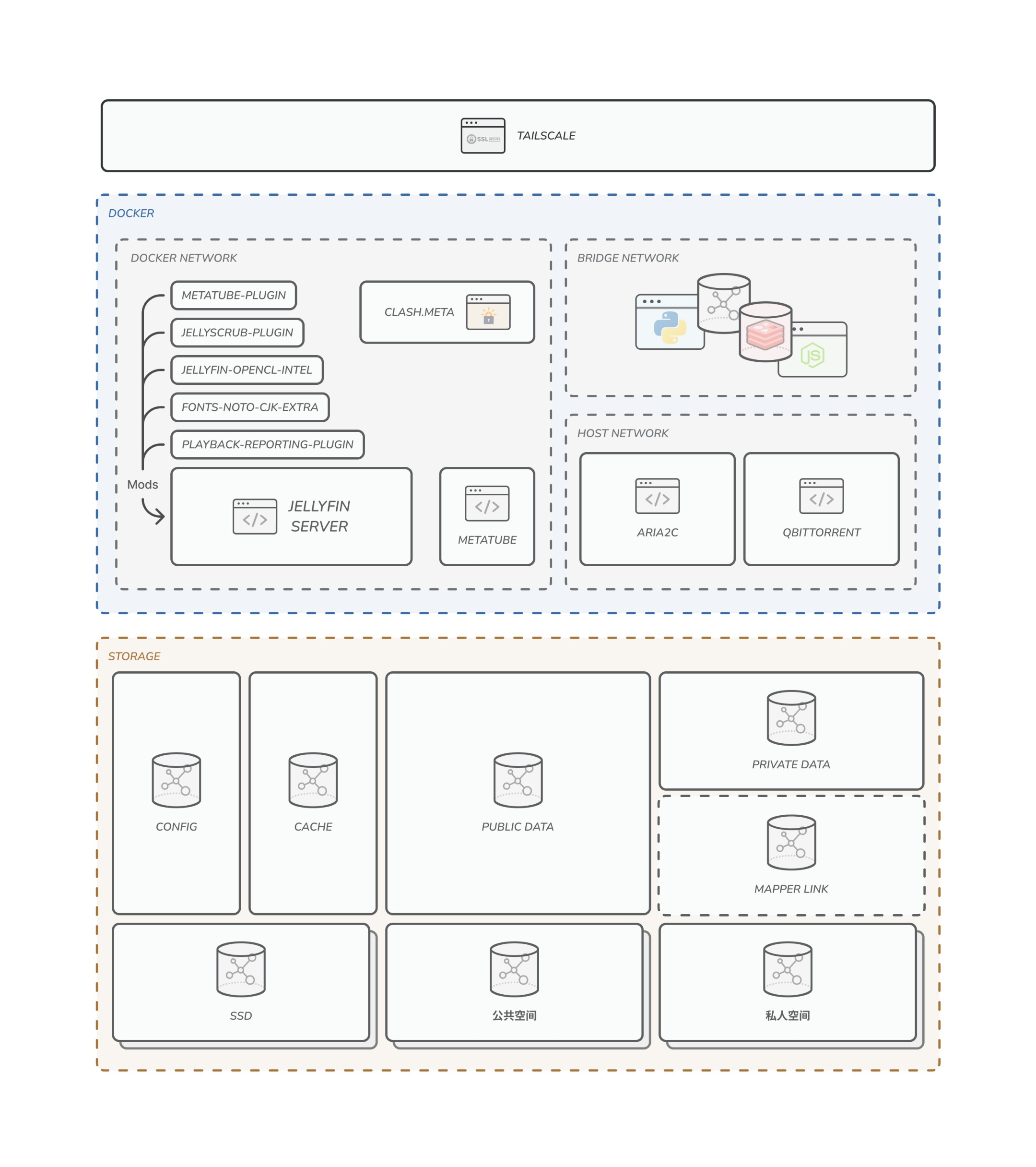
实际上最后要弄成这样(懒得弄箭头了,将就看吧):
紧急通知
①
先前 Intel N5105/6005 平台的 DSM 因为没有 Intel 核显驱动导致无法硬件解码的问题一直迟迟不能得到解决。但最近随着群晖 SA6400 系列平台 toolchain 开源,有开发者成功借助该平台的 toolchain 编译出 Intel i915 驱动,意味着核显硬解问题被突破,阻挡黑群的最后一座大山已经被顺利拆除。
https://xpenology.com/forum/topic/69865-i915-driver-for-sa6400/
因此,(刷了 DSM 的)绿联 DX4600 Pro 已经成为全网性价比最高的 4 盘位 NAS 成品机!
②
这篇文章暂停了一段时间,因为绿联官方说“即将迎来固件更新”,所以我就暂停了一阵子,因为怕现在写出来的内容会在系统更新后过时。
在官方的计划路线失踪了 1 个月、固件更新停摆了 2 个月之后,我们终于在 12 月 5 日迎来了 v4.9.0 的重大更新:他们花了 2 个月时间重构了相册,其他部分几乎是丝毫没变,因此本篇章所涉及的部署教程没有受到任何影响。
另外,我在《深度分析》中吐槽相册的问题,在这个重构的相册 2.0 中基本都被解决。
Tailscale
众所周知,绿联云所谓自带的 P2P 只有 APP 能够使用。APP 以外的任何服务,包括 docker 、你在系统环境内跑的各种各样的东西,公网访问还是要自己解决。
这篇教程将会使用大内网模式,即以 Tailscale 作为终端组网,其它所有想要访问 NAS 的用户都需要加入大内网。至于理由,我能够编出很多:
-
不依赖公网 IP
-
因为不依赖公网 IP ,所以相比 DDNS 等方案可操作性更强
-
因为不用 DDNS 域名,所以无需经过备案等繁琐操作
-
即使没有 TLS 证书,也是端到端加密,数据隐私有保障,不怕 HTTP 明文访问被“反诈中心”找上门
-
邀请用户入网需要二次验证,能够有效管控加入网络的用户
-
Tailscale 生态中的 Exit Node 、Taildrop 、MagicDNS 功能为用户间的联系提供了极大便利,有 MagicDNS 和手动定义 DNS 功能也能够保证访问体验不繁琐,不用记 IP
-
只有 Tailscale 真真正正做到了全平台覆盖,(几乎)任何内核完备的操作系统都能够运行 Tailscale ,包括容器。
(与此对比的是 ZeroTier ,它的 iOS 端不支持自定义 moon ,Android 官方客户端不支持自定义 Moon )
-
开放,全平台客户端一键填写
login-server,即使用 Headscale 自建网络客户端也无需进行接入 Moon 那种繁琐的步骤( Planet 仍是私有化产物,即 iOS 没有办法连接自建 planet )
-
穿透能力极强,甚至能够带动其它的 P2P 方案在上层线路打洞
(想必很多人没有体验过 ZeroTier 组网能 ping 通但是数据一直阻塞,启动 Tailscale 的瞬间两款软件的 P2P 突然全通了的事情)
-
我是 wireguard 神教拥护者
废话说完了,我们直接开始。Tailscale 客户端在 unix 系统需要使用/dev/net/tun来提供网络隧道,因此在容器中使用需要手动透传 device ,这一步操作在绿联私有云 APP 的 docker 管理器 UI 中无法实现。此外,受限于 docker 的网络机制,在容器中运行 Tailscale 仍有诸多限制。
我认为,在一个容器层级里跑 wireguard 多多少少是脑子出了问题。因此,我们将会把 Tailscale 直接安装在系统里,为系统全局的网络提供穿透服务。
添加 OPKG 软件源
vim /etc/opkg/distfeeds.conf
我们能够看到系统默认只在 distfeeds 里启用了 SNAPSHOT 源,基本上等同于常规的软件都不可用,所以需要手动添加 openwrt 22.03 的 packages:
src/gz openwrt_packages https://archive.openwrt.org/releases/22.03.0/targets/x86/64/packages
src/gz openwrt_base https://downloads.openwrt.org/releases/22.03.0/packages/x86_64/base
:wq保存,先更新源再安装依赖:
opkg update
opkg install libustream-openssl ca-bundle
安装 Tailscale
仅需一条命令
opkg install --force-depends tailscale tailscaled
安装进程一定会失败,Tailscale 无法运行,在后处理的时候会提示/usr/sbin/tailscale: not found,具体原因参考我们在深入解析中的 OPKG 分析环节。但是通过 OPKG 安装 tailscale 包,它会帮我们配置好/etc/init.d等配置文件,因此这一步是必要的。
好在,Tailscale 官方的 packages release 为普通 Linux 编译好了一份静态链接库的版本,接下来我们要做的是去 https://pkgs.tailscale.com/stable/#static 下载 amd64 平台的 Static binaries ,并且替换掉 OPKG 释放到系统里的 binaries 。
Static binaries 对比 OPKG 包安装的二进制文件:

下载这个:
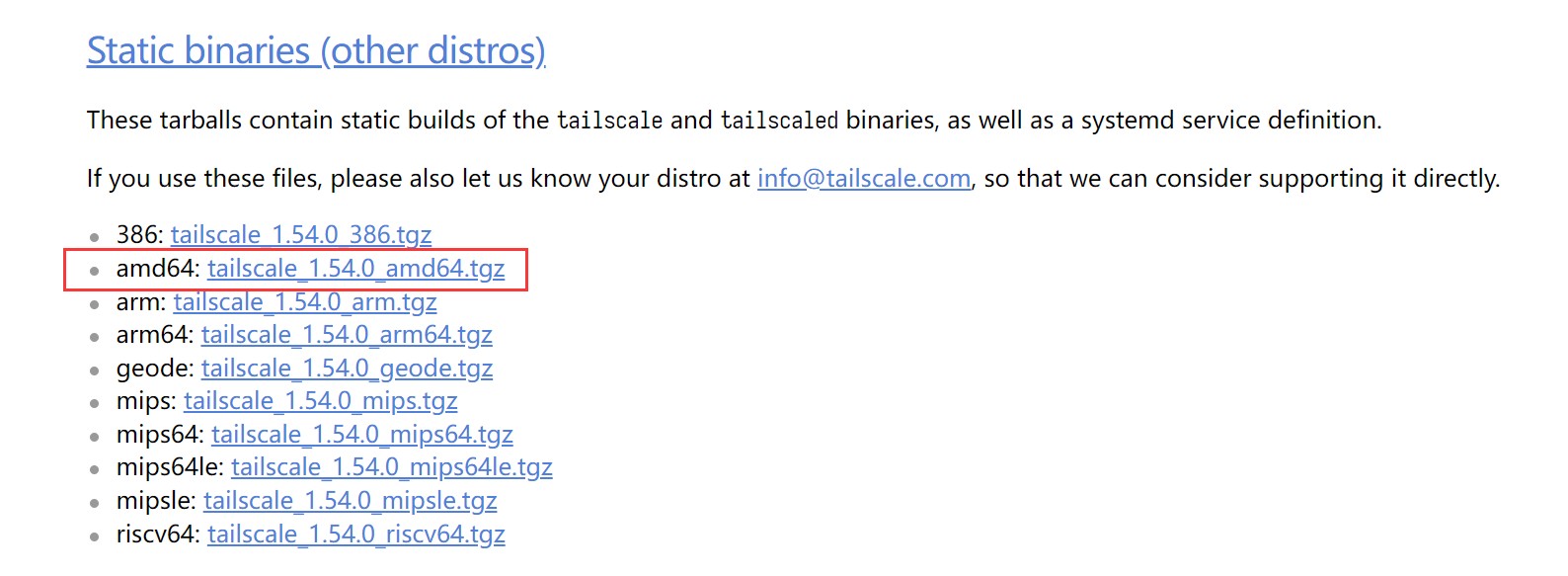
通过各种方式上传到服务器里,大概执行以下命令覆盖并授予执行权限:
tar zxvf tailscale<tab>
cp tailscale /usr/sbin
cp tailscaled /usr/sbin
chmod +x /usr/sbin/tailscale* # 或者模仿绿联的权限模式,777
然后通过init.d尝试启动 tailscale 服务,并查询是否 running:
/etc/init.d/tailscale restart
/etc/init.d/tailscale status
你会看到蹦出了一系列关于 iptables 的报错,这些错误都是因为 tailscale 尝试使用 iptables 去编辑 systemd.target 产生的,而众所周知 openwrt 并没有 systemd ,因此可以不用理会。
需要重点关注的是这些 log 之间是否有出现/usr/sbin/iptables: not found之类的错误,如果有,请参考 Troubleshooting ,否则代表后台服务 tailscaled 已经启动成功。
日志参考:
root@UGREEN-????:~# /etc/init.d/tailscale restart
logtail started
Program starting: v1.52.1-t75d3c9385-g3e9627f3b, Go 1.21.3: []string{"/usr/sbin/tailscaled", "--cleanup"}
LogID: ************************************
logpolicy: using system state directory "/var/lib/tailscale"
dns: [rc=unknown ret=direct]
dns: using "direct" mode
dns: using *dns.directManager
......
logtail started
Program starting: v1.52.1-t75d3c9385-g3e9627f3b, Go 1.21.3: []string{"/usr/sbin/tailscaled", "--cleanup"}
LogID: ************************************
logpolicy: using system state directory "/var/lib/tailscale"
dns: [rc=unknown ret=direct]
dns: using "direct" mode
dns: using *dns.directManager
deleting [-j ts-input] in filter/INPUT: running [/usr/sbin/iptables -t filter -D INPUT -j ts-input --wait]: exit status 2: iptables v1.8.7 (legacy): Couldn't load target `ts-input':No such file or directory
Try `iptables -h' or 'iptables --help' for more information.
deleting [-j ts-forward] in filter/FORWARD: running [/usr/sbin/iptables -t filter -D FORWARD -j ts-forward --wait]: exit status 2: iptables v1.8.7 (legacy): Couldn't load target `ts-forward':No such file or directory
Try `iptables -h' or 'iptables --help' for more information.
deleting [-j ts-postrouting] in nat/POSTROUTING: running [/usr/sbin/iptables -t nat -D POSTROUTING -j ts-postrouting --wait]: exit status 2: iptables v1.8.7 (legacy): Couldn't load target `ts-postrouting':No such file or directory
Try `iptables -h' or 'iptables --help' for more information.
deleting [-j ts-input] in filter/INPUT: running [/usr/sbin/ip6tables -t filter -D INPUT -j ts-input --wait]: exit status 2: ip6tables v1.8.7 (legacy): Couldn't load target `ts-input':No such file or directory
Try `ip6tables -h' or 'ip6tables --help' for more information.
deleting [-j ts-forward] in filter/FORWARD: running [/usr/sbin/ip6tables -t filter -D FORWARD -j ts-forward --wait]: exit status 2: ip6tables v1.8.7 (legacy): Couldn't load target `ts-forward':No such file or directory
Try `ip6tables -h' or 'ip6tables --help' for more information.
[RATELIMIT] format("deleting %v in %s/%s: %v")
cleanup: list tables: netlink receive: invalid argument
flushing log.
logger closing down
root@UGREEN-????:~# /etc/init.d/tailscale status
running
登录 Tailscale
由于这个绿联系统的各种组件错综复杂,端口开放关系混乱,所以我们希望 Tailscale 尽可能小地去影响系统的其它网络服务运行,具体来说:
- 不去接管系统的 DNS
- [Openwrt 系统必须]不去更改 iptables 规则
- [可选]不去创建子网路由
这会导致:
- 本机的 MagicDNS 失效,无法在本机通过域名访问其它设备,但是被访问不受影响
- Subnet Router 相关功能可能受限
考虑到 NAS 只是一个提供服务的受访终端,上述缺陷可以忽略不计。
因此,启动 Tailscale 必须使用以下参数:
tailscale up --netfilter-mode=off --accept-dns=false
如果你使用自建的 Headscale 服务器:
# 即使没有域名也建议使用 ZeroSSL 给纯 IP 上个 TLS 证书
tailscale login --login-server https://<your-server> --netfilter-mode=off --accept-dns=false
尽量避免使用--accept-routes flag ,在不传入这个 flag 的时候默认是 false 。必须使用--netfilter-mode=off参数!
接下来的验证步骤就跟普通 Linux 机是一样的,登录完成后即可使用,可以使用netcheck验证。
root@UGREEN-????:~# tailscale netcheck
2023/11/25 15:37:41 portmap: [v1] Got PMP response; IP: 100.64.***.***, epoch: 189968
2023/11/25 15:37:41 portmap: [v1] Got PCP response: epoch: 189968
2023/11/25 15:37:41 portmap: [v1] UPnP reply {Location:http://192.168.1.1:5351/rootDesc.xml Server:MiWiFi/x UPnP/1.1 MiniUPnPd/2.1 USN:uuid:**********************::urn:schemas-upnp-org:device:InternetGatewayDevice:1}, "HTTP/1.1 200 OK\r\nCACHE-CONTROL: max-age=120\r\nST: urn:schemas-upnp-org:device:InternetGatewayDevice:1\r\nUSN: uuid:***********************::urn:schemas-upnp-org:device:InternetGatewayDevice:1\r\nEXT:\r\nSERVER: MiWiFi/x UPnP/1.1 MiniUPnPd/2.1\r\nLOCATION: http://192.168.1.1:5351/rootDesc.xml\r\nOPT: \"http://schemas.upnp.org/upnp/1/0/\"; ns=01\r\n01-NLS: 1700703935\r\nBOOTID.UPNP.ORG: 1700703935\r\nCONFIGID.UPNP.ORG: 1337\r\n\r\n"
2023/11/25 15:37:41 portmap: UPnP meta changed: {Location:http://192.168.1.1:5351/rootDesc.xml Server:MiWiFi/x UPnP/1.1 MiniUPnPd/2.1 USN:uuid:*************************::urn:schemas-upnp-org:device:InternetGatewayDevice:1}
Report:
* UDP: true
* IPv4: yes, ***.***.***.***:*****
* IPv6: yes, [240e::****]:*****
* MappingVariesByDestIP: false
* HairPinning: true
* PortMapping: UPnP, NAT-PMP, PCP
* CaptivePortal: false
* Nearest DERP: Headscale Embedded DERP TC Shanghai 4Mbps
* DERP latency:
- headscale: 30.4ms (Headscale Embedded DERP TC Shanghai 4Mbps)
- sfo: 168.1ms (San Francisco)
- hkg: 174.4ms (Hong Kong)
- lax: 175.6ms (Los Angeles)
- tok: 178.7ms (Tokyo)
- den: 187.6ms (Denver)
- sea: 187.8ms (Seattle)
......
配置防火墙
由于我们使用--netfilter-mode=off模式登录 Tailscale ,所以软件不会去创建防火墙规则,我们需要根据Openwrt Wiki 的教程自行处理。实际上从 uci 内置规则来看,UGOS 默认是放行所有流量出入的,但是禁止了转发,可能会导致穿透能力被削弱的问题,因此我们还是按照教程走一遍:
Create a new unmanaged interface via LuCI: Network → Interfaces → Add new interface
- Name: tailscale
- Protocol: Unmanaged
- Device: tailscale0
Create a new firewall zone via LuCI: Network → Firewall → Zones → Add
- Name: tailscale
- Input: ACCEPT (default)
- Output: ACCEPT (default)
- Forward: ACCEPT
- Masquerading: on
- MSS Clamping: on
- Covered networks: tailscale
- Allow forward to destination zones: Select your LAN (and/or other internal zones or WAN if you plan on using this device as an exit node)
- Allow forward from source zones: Select your LAN (and/or other internal zones or leave it blank if you do not want to route LAN traffic to other tailscale hosts)
Click Save & Apply
这段教程是面向 luci 的,然而我们的系统并没有 luci ,所以翻译成 uci 命令就是这样:
uci add network interface
uci set network.@interface[-1].name='tailscale'
uci set network.@interface[-1].proto='none'
uci set network.@interface[-1].ifname='tailscale0'
uci commit network
uci add firewall zone
uci set firewall.@zone[-1].name='tailscale'
uci set firewall.@zone[-1].input='ACCEPT'
uci set firewall.@zone[-1].output='ACCEPT'
uci set firewall.@zone[-1].forward='ACCEPT'
uci set firewall.@zone[-1].network='tailscale'
uci set firewall.@zone[-1].masq='1'
uci set firewall.@zone[-1].mtu_fix='1'
uci commit firewall
uci add firewall forwarding
uci set firewall.@forwarding[-1].src='tailscale'
uci set firewall.@forwarding[-1].dest='wan'
uci commit firewall
# 可选
uci add firewall forwarding
uci set firewall.@forwarding[-1].src='wan'
uci set firewall.@forwarding[-1].dest='tailscale'
uci commit firewall
创建完这些规则之后,我建议重启,或者如果你不想重启:
/etc/init.d/network restart
/etc/init.d/firewall reload # 使用 restart 命令强行重启防火墙会导致 docker 网络崩溃
Troubleshooting
如果出现 iptables not found ,可能是因为通过 OPKG 或者其他手段安装的一些包影响了 iptables 的调用。以我的经验为例,如果参照了 Openwrt 的官方教程去手动安装了iptables-nft包的话,就会导致 iptables 失效,原厂环境下实际上是能用的。
无需担心因为安装了这个包,系统的 iptables 直接失能。因为iptables-nft本质上是给 iptables 相关的几个命令添加了指向/usr/sbin/xtables-legacy-multi的软链接,并没有替换本身可以执行的二进制。但是很魔幻的事情是,通过 OPKG 安装的软链接是失效的,但是你将它删除,再手动创建一遍相同的链接却又可以正常使用,目前还没找出原因。
所以:
rm /usr/sbin/iptables
rm /usr/sbin/ip6tables
ln -s /usr/sbin/xtables-legacy-multi /usr/sbin/iptables
ln -s /usr/sbin/xtables-legacy-multi /usr/sbin/ip6tables
这会保证 tailscaled 初始化的时候能够正常运行,否则整个 tailscale 服务都无法拉起。
Docker 的网络搭建
Docker 的 bridge 网络会随机为容器分配 NAT 地址,为了方便容器内部之间互相访问,它为具名网络提供了通过 container name 解析到 IP 的能力。
在这个系统架构中,我们决定把隧道服务搭建在容器里,并且只提供被动的 Proxy 接口访问能力,为一些需要代理的容器提供服务,不干扰系统其它网络环境的运行,做到职责最小化。
为了更好管理需要隧道的容器,我们将会为它专门创建一个 NAT 网络,并把需要隧道的容器都放在这个网络里。
给 bridge 开启 IPV6
Docker 默认的 bridge 网络是关闭 IPV6 的,所以我们需要通过更改配置的方法主动开启 bridge 的 IPV6 。这一步并不影响其它容器的部署,只是为了给整个 docker 平台创建一致且可用的 IPV6 环境。
vim /etc/docker/daemon.json
{
"data-root": "......",
"log-level": "warn",
"iptables": true,
"api-cors-header": "*",
"hosts": [
"unix:///var/run/docker.sock",
"tcp://127.0.0.1:9375"
],
"registry-mirrors": [
"https://registry.docker-cn.com"
],
/* 加上这几行配置 */
"ipv6": true,
"fixed-cidr-v6": "2001:db8:abc1::/64", // 并不需要严格遵守这里的 cidr ,任意一个内网 IPV6 网段皆可
"experimental": true,
"ip6tables": true
}
保存后在绿联私有云 APP 的 docker 管理页中重启,这时候你就能够看到 bridge 网络已经具备 IPV6 地址。

创建一个新的 NAT 网络
这一步不需要命令行,直接在 APP 操作即可。网络名称任选,子网和网关的填写方法请复习网络基础知识。如果实在不知道该选什么网段,就去问 chatGPT 给你随机生成一个。一个例子:
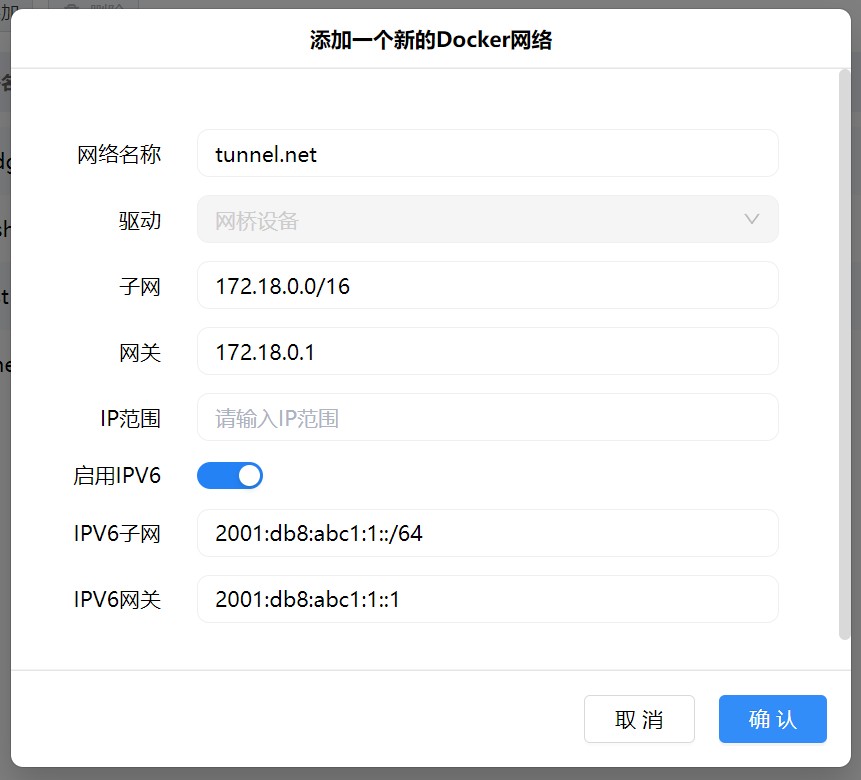
第一个容器
所谓大内网计划,我们要部署的第一个容器一定是隧道。我们这里以 meta 为例,虽然这个内核的一系列衍生项目全部都删库跑路,但是我在他们消失于互联网之前备份下了:
- 所有的源码
- 最近 3 个版本 stable 和若干 nightly 的 releases
- 最近 3 个以上版本的 docker image tar 包
注:有需要的话请留下联系方式
将clash-meta-pr-837.tar上传到 NAS 中,并在 SSH 通过以下命令导入 tar 包镜像,它会自动识别,然后使用这个镜像创建容器:
docker load <image>.tar
控制台“从设备导入”tar 包,使用的似乎是docker import,会丢失所有的元数据信息。
因为 bridge 网络内支持通过 container name 访问,所以在这里我们部署的所有容器,都使用‘.’作为分隔符号,好让请求看起来更像是一个 URL ,比如这样:
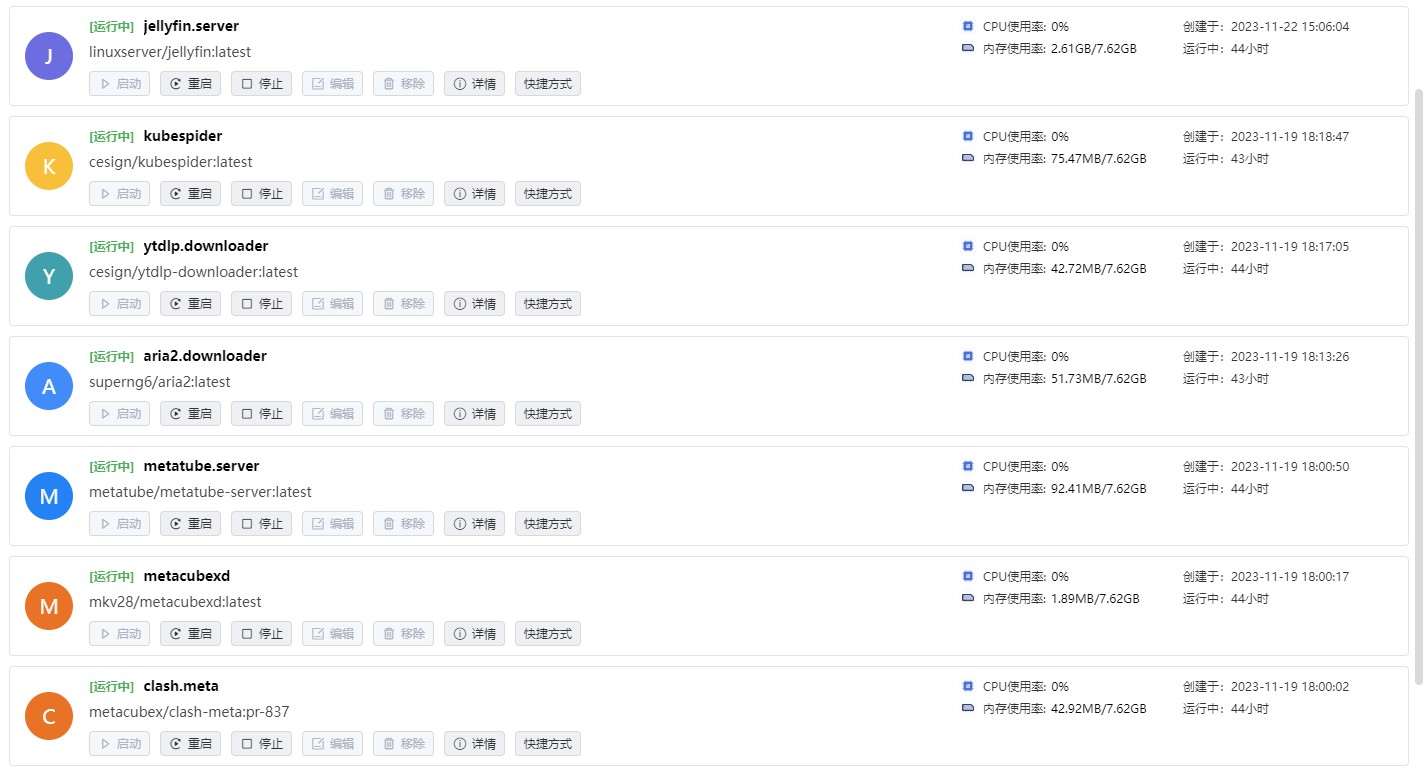
容器大概的配置如下:
| Config | Value |
|---|---|
| -i | True |
| -t | True |
| --restart | unless-stopped |
| 容器能力 | 建议勾选NET_ADMIN和NET_BROADCAST(不一定正确) |
| 网络 | 你刚建的tunnel.net |
| 存储空间映射 | 存储空间/config/clash:/root/.config/clash/, RW |
| 端口映射 | TCP 7890:7890, TCP 9090:9090, TCP+UDP 1053:1053 |
使用 meta ,一是因为它能够默认支持订阅管理,不用像原生内核那样只能够指定一个本地的配置文件,方便远程维护和更新;二是因为它的订阅与规则解耦,我们可以无视订阅附带的规则内容自行添加一些网络环境相关的规则(也就是 Mixin 和 Parser )。
配置文件
直接照抄虚空终端 Docs 里的懒人配置,再把自己的订阅链接填上就好: https://wiki.metacubex.one/example/#_2 ,并且我推荐直接把geox-url节点里三个地理信息文件手动下载下来放到你的存储空间 config 映射文件夹里去,在 docker 容器内自动下载失败的概率比较大。
但我们需要做一些改动,首先需要把 tun 模式直接关闭:
tun:
enable: false
......
其次,主控相关的规则也需要有所更改:
mode: rule
ipv6: true # 如果你的网络环境支持 IPV6 ,记得打开
log-level: info
allow-lan: true # 必须允许 LAN 访问
bind-address: '*' # 当系统同时具有多张网卡( tailscale 虚拟出来的 tun 网卡)时,
# 这里只能够填'*'全监听,因为该条目只支持 string ,不支持 array
authentication: # 建议随机一个非常强的用户和密码,防止被公网使用
- "YouCannotUseThis:ICannotUseThisQAQ"
skip-auth-prefixes:
- 127.0.0.1/8 # 本地回环
- ::1/128 # 本地回环 IPV6
- 172.19.0.0/16 # Docker network 网段
- 192.168.1.0/24 # 路由器 LAN
- 100.***.***.*/22 # Tailscale 网段
- fd7a:****:****::/48 # Tailscale IPV6 网段
- 2001:db8:abc1:1::/64 # Docker network IPV6 网段
- 240e:3b5:34e1:93f0::1/64 # 路由器 LAN IPV6
mixed-port: 7890
unified-delay: false
tcp-concurrent: true
external-controller: 0.0.0.0:9090 # 控制端口监听全网段
这里我们设置了隧道监听全网,但是配置了一个非常复杂(不用记)的 Authentication 验证,以确保来自公网的用户不能够白嫖,同时放行四个网段:localhost 、docker network 、tailscale 、LAN ,在这 4 个网段内的用户可以正常访问隧道。
接下来我们还要修改 DNS 和 Rules 的相关规则,使得内核能够识别来自容器间的域名和 IP 段,将他们放行,否则默认情况下会被丢进 match 规则从而导致请求方向失控。
dns:
enable: true
listen: :1053
ipv6: true
enhanced-mode: fake-ip
......
nameserver:
- ......
- 127.0.0.11 # Docker 对容器提供的 DNS 地址,非常重要
# 没有这条将导致内核无法解析 container 名
......
nameserver-policy:
"geosite:cn,private":
- https://doh.pub/dns-query
- https://dns.alidns.com/dns-query
rules:
# 将你的容器名和 docker network 网段全部指定为 DIRECT ,放在配置最前面
- DOMAIN-SUFFIX,jellyfin.server,DIRECT
- DOMAIN-SUFFIX,metatube.server,DIRECT
- DOMAIN-SUFFIX,*.downloader,DIRECT
- IP-CIDR,172.19.0.0/16,DIRECT,no-resolve
- IP-CIDR6,2001:db8:abc1:1::/64,DIRECT,no-resolve
- ......
一些容器一旦在环境变量中指定了HTTP_PROXY和HTTPS_PROXY后,所有的 request 流量都会绕它走一圈,因此需要配置这样的放行规则,以避免请求走丢。
当配置文件改写好,三个 geox 也放在 config 文件夹里后,就可以启动容器待命。
远程管理
远程管理不用自建服务器。Meta 提供了一个配套的前端项目 MetaCubeXD ,并且写成了 PWA 应用。
因为我们在 LAN 互访都是基于 HTTP 的,所以正常情况下直接打开他们的 Demo 页,即 https://metacubexd.pages.dev/会被浏览器安全策略阻止,无法连接到内核。我建议直接点击 Chrome 浏览器右上角的安装,在本地生成一个快捷方式:
然后在 chrome://settings/content 里搜索 pages.dev ,找到 metacubexd ,将“不安全内容”的权限设置为允许:

现在,通过 metacubexd PWA 即可访问内核。虽然顶部会有一个比较丑的“不安全”Banner ,但无伤大雅,能用。
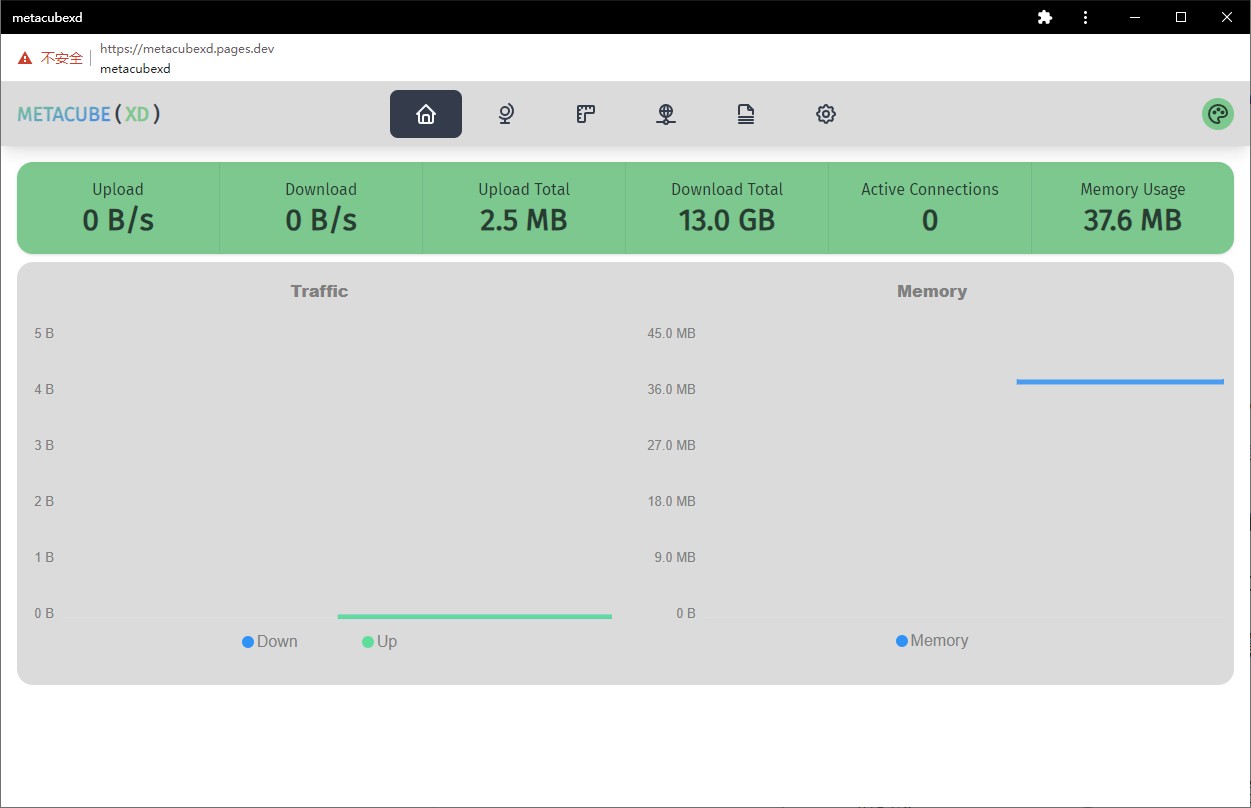
如果你想要自建 Docker ,mkv28/metacubexd镜像似乎是第三方作者封装的,很久没有更新,版本已经严重过时,还是推荐使用官方 demo 安装 PWA 。
互访案例
现在以一个 Jellyfin/Emby 使用的面向特定领域的资源刮削插件服务后端 metatube 为例,这个镜像已经支持在环境变量中指定HTTP_PROXY和HTTPS_PROXY,所以我们直接将这个容器创建到 tunnel.net 中,同时指定相关的环境变量:
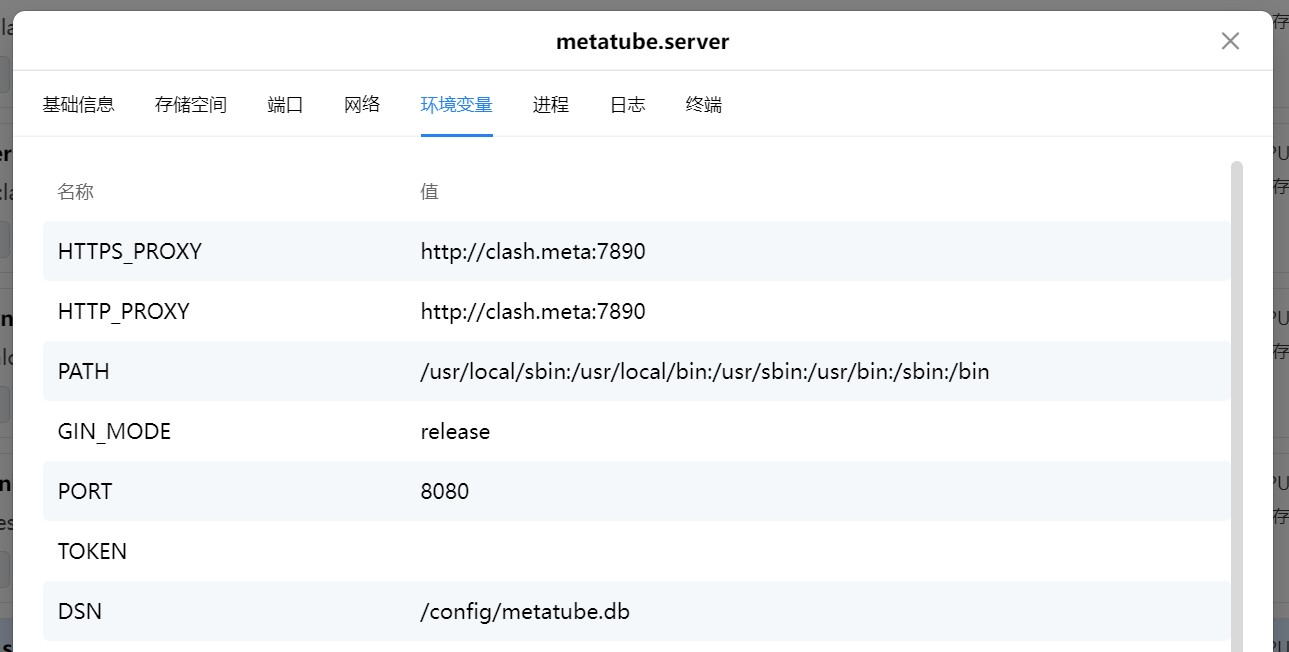
与此同时,在 Jellyfin Plugin 设置里,指定后端地址为 container name ,端口是容器内部定义的 PORT,而不是在容器启动时指定的对外的映射端口:
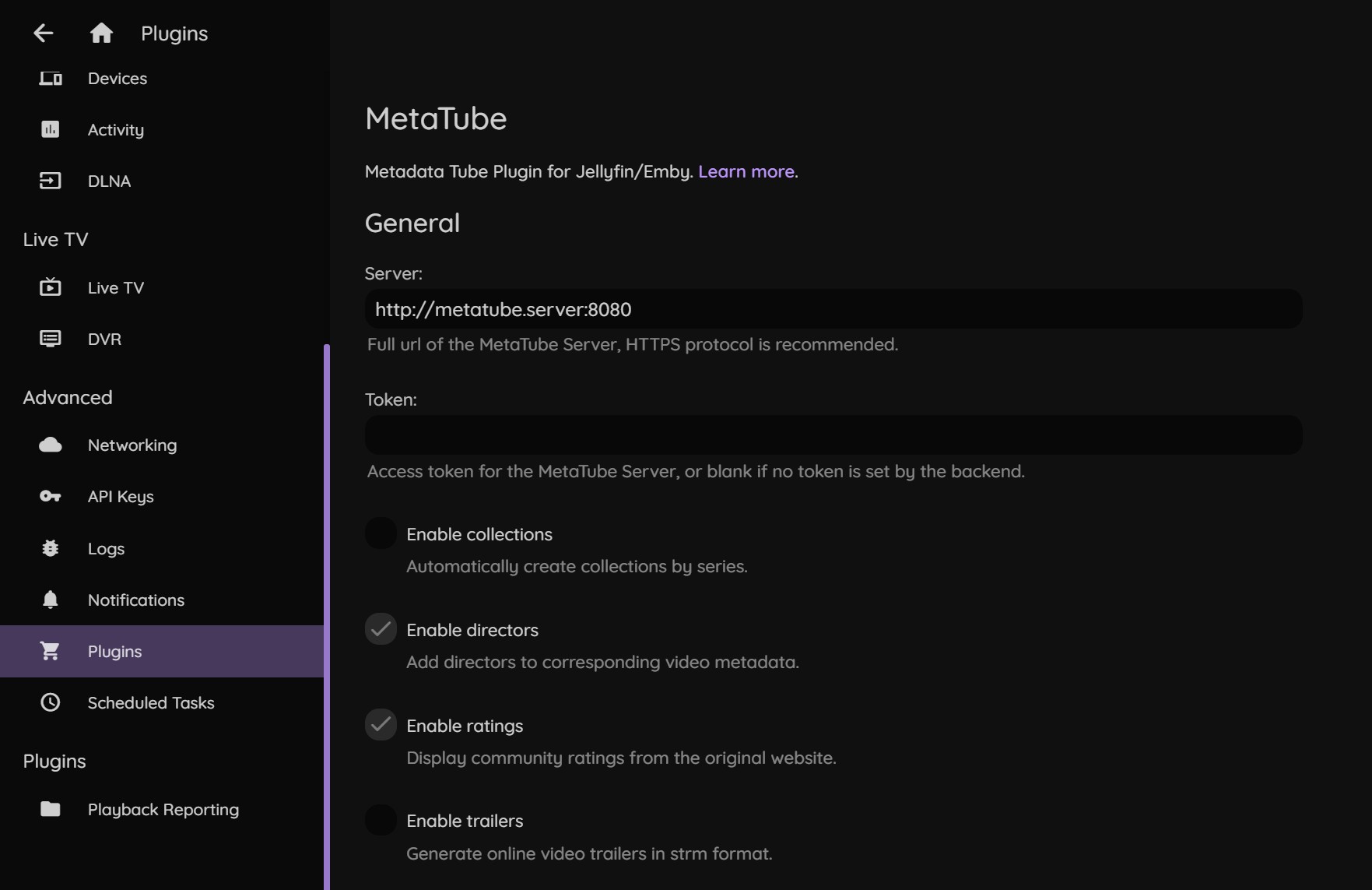
接下来,尝试请求刮削一个视频的 metadata ,在 docker logs 中查看内核的连接走向:
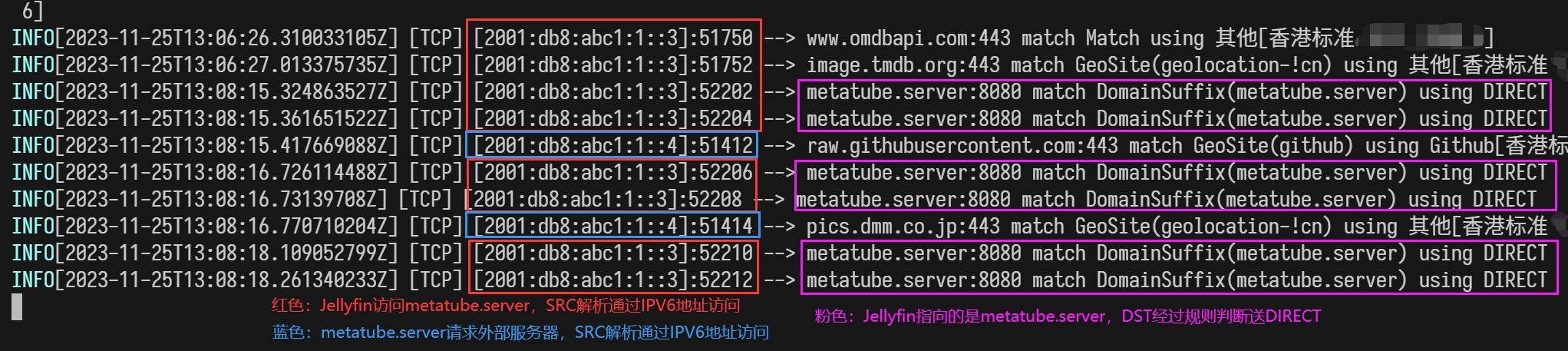
无论是 SRC 还是 DST 的路由都没有问题。
Docker 挂载公共空间的方案
对于大多数使用 NAS 的用户而言,把自己收集的影视内容放到公共空间供其他人观看下载,同时把文件映射到自建的媒体服务器,是一个正常不过的需求。但是绿联的脑缺产品经理剑走偏锋,创新地想出了“Docker 不能挂载公共空间”的机制,为他的聪明点赞!
好在 docker 是一个遵守 Linux 规范的软件,所以在挂载 bind volume 时,允许通过软链接进行寻址。因此现阶段的解决方案是,在私人空间里单独腾出一个文件夹,创建你想要访问公共空间地址的软链接:
ln -s <公共空间位置> <私人空间位置>
在我这里,所有的软链接都放在私人空间中名为 public-mapping 的文件夹,方便管理。你在挂载目录的时候可以挂载到软链接本身,也可以沿着软链接继续挂载其子文件夹,都没有问题。
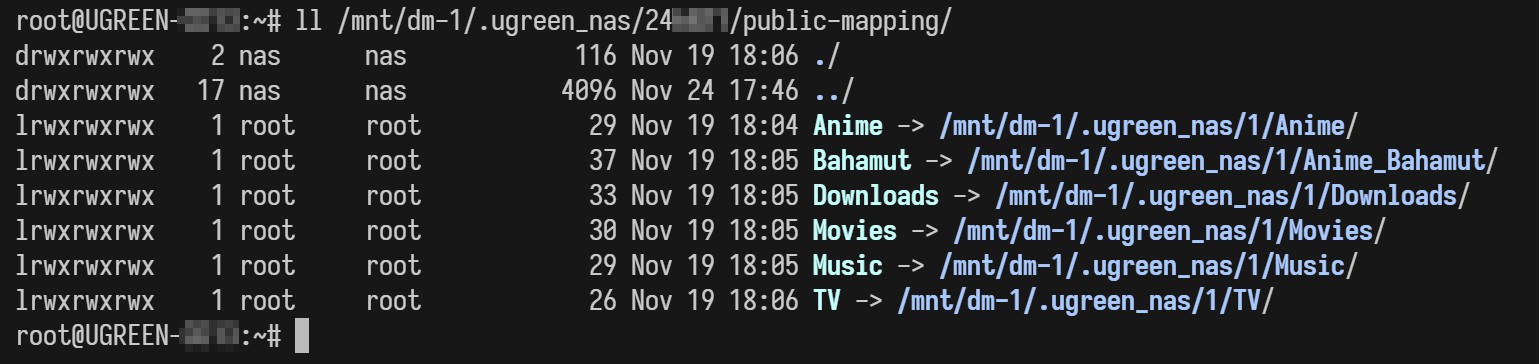
我看到有些教程教人用硬链接,不要使用硬链接,除非你知道自己在做什么!
不要使用硬链接,除非你知道自己在做什么!
不要使用硬链接,除非你知道自己在做什么!
为什么 docker 不能挂公共空间?
让我们复习《深入解析》吧:
某些 docker 镜像支持通过 PGID 和 PUID 环境变量指定宿主机的用户身份,这个身份会影响 bind volume 产生的文件属性,并且假设默认的 permission mask 是 022 的话,产生的数据和配置文件通过“网络账户”登录的 SMB 是没有修改权限( 755 )的,在修改映射到硬盘的配置文件时会出现一些麻烦。
其实这只是一个潜在的问题,因为 SMB 根本没有开放给非管理员使用,就算影响也只会影响管理员自己挂的 SMB 。
字数超限,V2EX 发帖有 30 分钟 CD ,下半部分待会儿见
第 1 条附言 · 2023-12-11 20:35:48 +08:00
系列文章已完结,第4篇点击跳转
 |
1
ccxuy 2024-01-23 20:37:38 +08:00
为什么不能用硬链接?软链接在 docker 里容易没法找到 host 对应的路径
|
 |
2
sheng9632 2024-02-19 14:35:48 +08:00
LZ 画图是拿什么软件画的?
|
 |
3
peyppicp 2024-05-08 21:16:53 +08:00
拜读了,牛逼
|