
这是一个创建于 2047 天前的主题,其中的信息可能已经有所发展或是发生改变。

导读
身处在现在这个大数据时代,我们处理的数据量需以 TB 、PB, 甚至 EB 来计算,怎么处理庞大的数据集是从事数据库领域人员的共同问题。解决这个问题的核心在于,数据库中存储的数据是否都是有效的、有用的数据,因此如何提高数据中有效数据的利用率、将无效的过期数据清洗掉,便成了数据库领域的一个热点话题。在本文中我们将着重讲述如何在数据库中处理过期数据这一问题。
在数据库中清洗过期数据的方式多种多样,比如存储过程、事件等等。在这里笔者举个例子来简要说明 DBA 经常使用的存储过程 + 事件来清理过期数据的过程。
存储过程 + 事件清洗数据
存储过程( procedure )
存储过程是由一条或多条 SQL 语句组成的集合,当对数据库进行一系列的读写操作时,存储过程可将这些复杂的操作封装成一个代码块以便重复使用,大大减少了数据库开发人员的工作量。通常存储过程编译一次,可以执行多次,因此也大大的提高了效率。
存储过程有以下优点:
- 简化操作,将重复性很高的一些操作,封装到一个存储过程中,简化了对这些 SQL 的调用
- 批量处理,SQL + 循环,减少流量,也就是“跑批”
- 统一接口,确保数据的安全
- 一次编译多次执行,提高了效率。
以 MySQL 为例,假如要删除数据的表结构如下:
mysql> SHOW CREATE TABLE person;
+--------+---------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+---------------------------------------------------------------------------------------------------------------------------------+
| person | CREATE TABLE `person` (
`age` int(11) DEFAULT NULL,
`inserttime` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+---------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
创建一个名为 person 的表,其中 inserttime 字段为 datetime 类型,我们用 inserttime 字段存储数据的生成时间。
创建一个删除指定表数据的存储过程,如下:
mysql> delimiter //
mysql> CREATE PROCEDURE del_data(IN `date_inter` int)
-> BEGIN
-> DELETE FROM person WHERE inserttime < date_sub(curdate(), interval date_inter day);
-> END //
mysql> delimiter ;
创建一个名为 del_data 的存储过程,参数 date_inter 指定要删除的数据距离当前时间的天数。当表 person 的 inserttime 字段值( datetime 类型)加上参数 date_inter 天小于当前时间,则认为数据过期,将过期的数据删除。
事件( event )
事件是在相应的时刻调用的过程式数据库对象。一个事件可调用一次,也可周期性的启动,它由一个特定的线程来管理,也就是所谓的“事件调度器”。
事件和触发器类似,都是在某些事情发生的时候启动。当数据库上启动一条语句的时候,触发器就启动了,而事件是根据调度事件来启动的。由于它们彼此相似,所以事件也称为临时性触发器。事件调度器可以精确到每秒钟执行一个任务。
如下创建一个事件,周期性的在某个时刻调用存储过程,来进行清理数据。
mysql> CREATE EVENT del_event
-> ON SCHEDULE
-> EVERY 1 DAY
-> STARTS '2020-03-20 12:00:00'
-> ON COMPLETION PRESERVE ENABLE
-> DO CALL del_data(1);
创建一个名为 del_event 的事件,该事件从 2020-03-20 开始,每天的 12:00:00 执行存储过程 del_data(1)。
然后执行:
mysql> SET global event_scheduler = 1;
打开事件。这样事件 del_event 就会在指定的时间自动在后台执行。通过上述的存储过程 del_data 和事件 del_event,来达到定时自动删除过期数据的目的。
TTL ( Time To Live ) 清洗数据
通过上述存储过程和事件的组合可以定时清理数据库中的过期数据。图数据库 Nebula Graph 提供了更加简单高效的方式--使用 TTL 的方式来自动清洗过期数据。
使用 TTL 方式自动清洗过期数据的好处如下:
- 简单方便
- 通过数据库系统内部逻辑进行处理,安全可靠
- 数据库会根据自身的状态自动判断是否需要处理,如果需要处理,将在后台自动进行处理,无需人工干预。
TTL 简介
TTL,全称 Time To Live,用来指定数据的生命周期,数据时效到期后这条数据会被自动删除。在图数据库 Nebula Graph 中,我们实现 TTL 功能,用户设置好数据的存活时间后,在预定时间内系统会自动从数据库中删除过期的点或者边。
在 TTL 中,过期数据会在下次 compaction 时被删除,在下次 compaction 之前,query 会过滤掉过期的点和边。
图数据库 Nebula Graph 的 TTL 功能需 ttl_col 和 ttl_duration 两个字段一起使用,到期阈值是 ttl_col 指定的属性对应的值加上 ttl_duration 设置的秒数。其中 ttl_col 指定的字段的类型应为 integer 或 timestamp,ttl_duration 的计量单位为秒。
TTL 读过滤
针对 tag / edge,Nebula Graph 在 TTL 中将读数据过滤逻辑下推到 storage 层进行处理。在 storage 层,首先获取该 tag / edge 的 TTL 信息,然后依次遍历每个顶点或边,取出 ttl_col 字段值,根据 ttl_duration 的值加上 ttl_col 列字段值,跟当前时间的时间戳进行比较,判断数据是否过期,过期的数据将被忽略。
TTL compaction
RocksDB 文件组织方式
图数据库 Nebula Graph 底层存储使用的是 RocksDB,RocksDB 在磁盘上的文件是分为多层的,默认是 7 层,如下图所示:
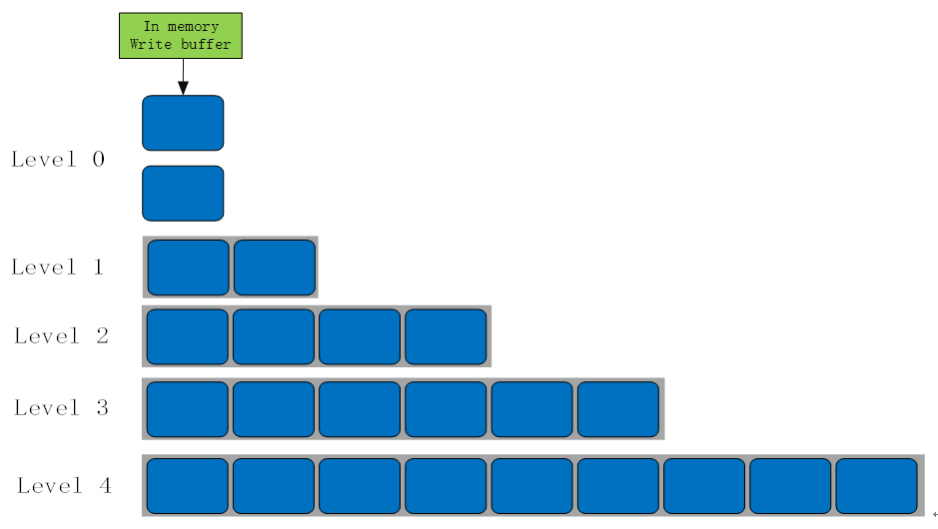
SST 文件在磁盘上的组织方式
Level 0 层包含的文件,是由内存中的 Memtable flush 到磁盘,生成的 SST 文件,单个文件内部按 key 有序排列,文件之间无序。其它 Level 上的多个文件之间都是按照 key 有序排列,并且文件内也有序,如下图所示:
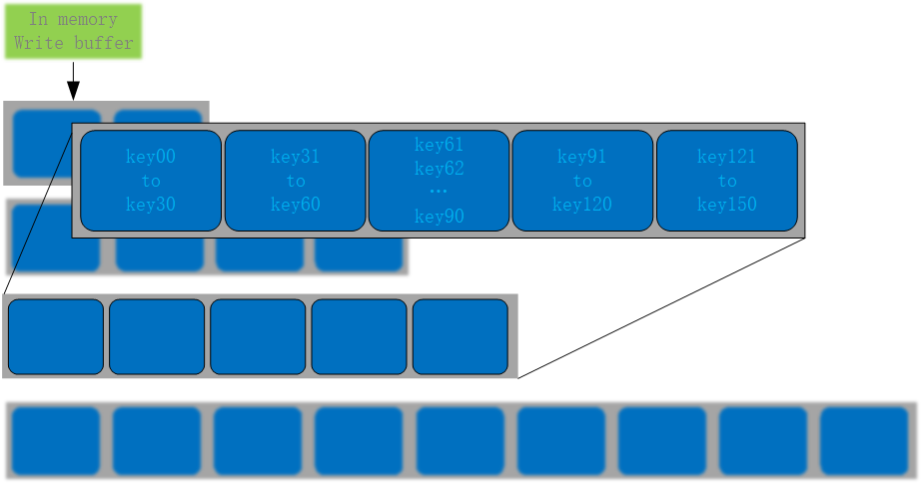
非 Level 0 层的文件数据划分
RocksDB compaction 原理
RocksDB 是基于 LSM 实现,但 LSM 并不是一个具体的数据结构,而是一种数据结构的概念和设计思想,具体细节参考LSM 论文。而 LSM 中最重要部分就是 compaction,由于数据文件采用 Append only 方式写入,而对于过期的数据,重复的、已删除的数据,需要通过 compaction 进行逐步的清理。
RocksDB compaction 逻辑
我们采用的 RocksDB 的 compaction 策略为 Level compaction 。当数据写到 RocksDB 时,会先将数据写入到一个 Memtable 中,当一个 Memtable 写满之后,就会变成 Immutable 的 Memtable 。RocksDB 在后台通过一个 flush 线程将这个 Memtable flush 到磁盘,生成一个 Sorted String Table (SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会与 Level 1 层进行 compaction 。通常必须将 Level 0 的所有文件 compaction 到 Level 1 中,因为 Level 0 的文件的 key 是有交叠的。
Level 0 与 Level 1 的 compaction 如下:
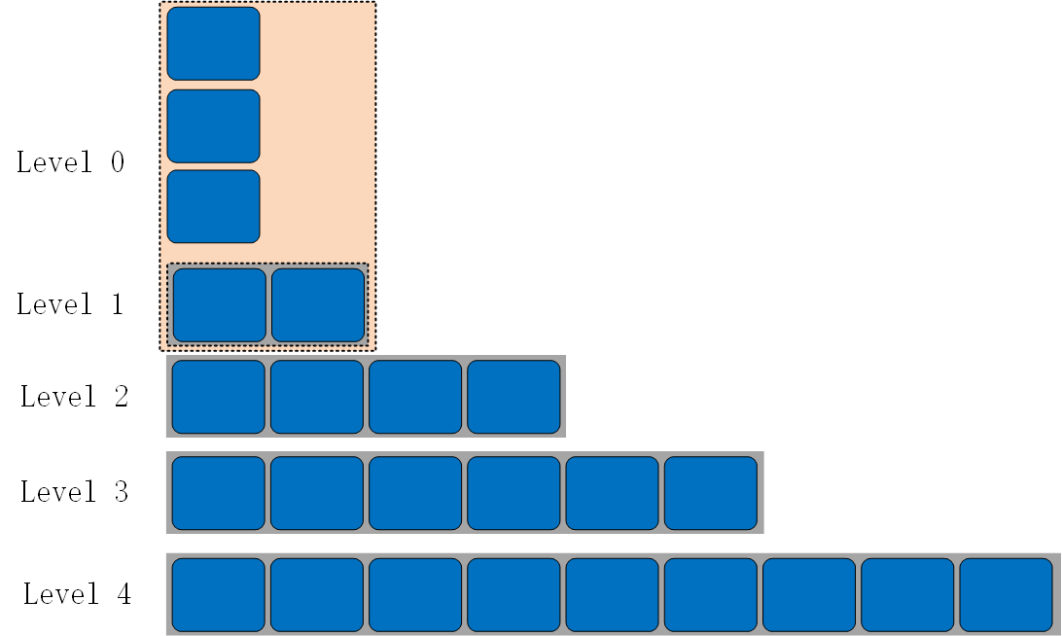
Level 0 与 Level 1 的 compaction
其他 Level 的 compaction 规则一样,以 Level 1 与 Level 2 的 compaction 为例进行说明,如下所示:
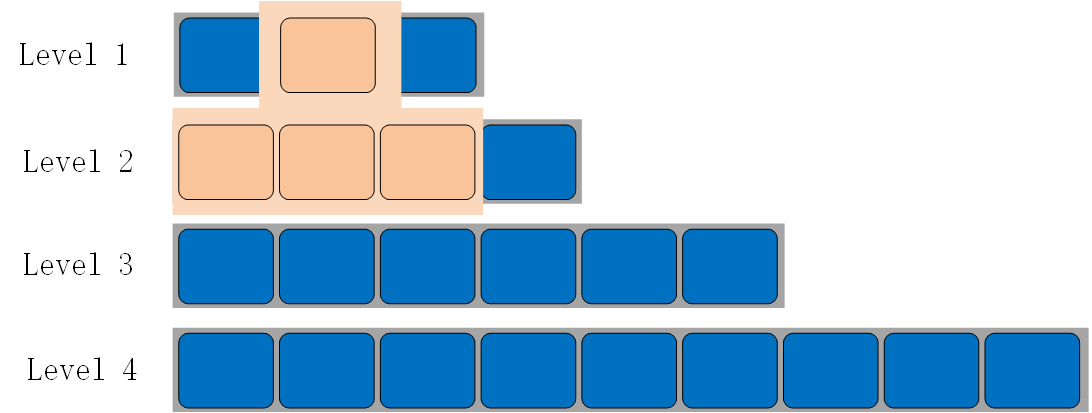
Level 1 与 Level 2 的 compaction
当 Level 0 compaction 完成后,Level 1 的文件总大小或者文件数量可能会超过阈值,触发 Level 1 与 Level 2 的 compaction 。从 Level 1 层至少选择一个文件 compaction 到 Level 2 的 key 重叠的文件中。compaction 后可能会触发下一个 Level 的 compaction,以此类推。
如果没有 compaction,写入是非常快的,但这样会造成读性能降低,同样也会造成很严重的空间放大问题。为了平衡写入、读取、空间三者的关系,RocksDB 会在后台执行 compaction,将不同 Level 的 SST 进行合并。
TTL compaction 原理
除了上述默认的 compaction 操作外( sst 文件合并),RocksDB 还提供了 CompactionFilter 功能,可以让用户自定义个性化的 compaction 逻辑。Nebula Graph 使用了这个 CompactionFilter 来定制本文讨论的 TTL 功能。该功能是 RocksDB 在 compaction 过程中,每读取一条数据时,都会调用一个定制的 Filter 函数。TTL compaction 的实现方法就是在 Filter 函数中实现 TTL 过期数据删除逻辑,具体如下:
- 首先获取 tag / edge 的 TTL 信息
- 然后遍历每个顶点或边数据,取出 ttl_col 列字段值
- 根据 ttl_duration 的值加上 ttl_col 列字段值,跟当前时间的时间戳进行比较,然后判断数据是否过期,过期的数据将被删除。
TTL 用法
在图数据库 Nebula Graph 中,edge 和 tag 实现逻辑一致,在这里仅以 tag 为例,来介绍 Nebula Graph 中 TTL 用法。
创建 TTL 属性
Nebula Graph 中使用 TTL 属性分为两种方式:
create tag 时指定 ttl_duration 来表示数据的持续时间,单位为秒。ttl_col 指定哪一列作为 TTL 列。语法如下:
nebula> CREATE TAG t (id int, ts timestamp ) ttl_duration=3600, ttl_col="ts";
当某一条记录的 ttl_col 列字段值加上 ttl_duration 的值小于当前时间的时间戳,则该条记录过期,否则该记录不过期。
- ttl_duration 的值为非正数时,则点的此 tag 属性不会过期
- ttl_col 只能指定类型为 int 或者 timestamp 的列名。
或者 create tag 时没有指定 TTL 属性,后续想使用 TTL 功能,可以使用 alter tag 来设置 TTL 属性。语法如下:
nebula> CREATE TAG t (id int, ts timestamp );
nebula> ALTER TAG t ttl_duration=3600, ttl_col="ts";
查看 TTL 属性
创建完 tag 可以使用以下语句查看 tag 的 TTL 属性:
nebula> SHOW CREATE TAG t;
=====================================
| Tag | Create Tag |
=====================================
| t | CREATE TAG t (
id int,
ts timestamp
) ttl_duration = 3600, ttl_col = id |
-------------------------------------
修改 TTL 属性
可以使用 alter tag 语句修改 TTL 的属性:
nebula> ALTER TAG t ttl_duration=100, ttl_col="id";
删除 TTL 属性
当不想使用 TTL 属性时,可以删除 TTL 属性:
可以设置 ttl_col 字段为空,或删除配置的 ttl_col 字段,或者设置 ttl_duration 为 0 或者 -1 。
nebula> ALTER TAG t1 ttl_col = ""; -- drop ttl attribute
删除配置的 ttl_col 字段:
nebula> ALTER TAG t1 DROP (a); -- drop ttl_col
设置 ttl_duration 为 0 或者 -1:
nebula> ALTER TAG t1 ttl_duration = 0; -- keep the ttl but the data never expires
举例
下面的例子说明,当使用 TTL 功能,并且数据过期后,查询该 tag 的数据时,过期的数据被忽略。
nebula> CREATE TAG t(id int) ttl_duration=100, ttl_col="id";
nebula> INSERT VERTEX t(id) values 102:(1584441231);
nebula> FETCH prop on t 102;
Execution succeeded (Time spent: 5.945/7.492 ms)
注意:
- 当某一列作为 ttl_col 值的时候,不允许 change 该列。 必须先移除 TTL 属性,再 change 该列。
- 对同一 tag,index 和 TTL 功能不能同时使用。即使 index 和 TTL 创建于不同列,也不可以同时使用。
edge 同 tag 的逻辑一样,这里就不在详述了。
TTL 的介绍就到此为止了,如果你对图数据库 Nebula Graph 的 TTL 有改进想法或其他要求,欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.io/ 的 Feedback 分类下提建议 👏
作者有话说:Hi,我是 panda sheep,是图数据库 Nebula Graph 研发工程师,对数据库领域非常感兴趣,也有自己的一点点心得,希望写的经验分享能给大家带来帮助,如有不当之处也希望能帮忙纠正,谢谢~
1 条回复 • 2020-03-25 21:21:29 +08:00
 |
1
dengxufan 2020-03-25 21:21:29 +08:00
学习了
|