
这是一个创建于 2573 天前的主题,其中的信息可能已经有所发展或是发生改变。
在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况。此时你是怎么操作的呢?逐一 SSH 登录每个服务器,使用 git 拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新?
有时候爬虫只需要在一个服务器上面运行,有时候需要在 200 个服务器上面运行。你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在 Redis 里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行?
A 爬虫已经在所有服务器上面部署了,现在又做了一个 B 爬虫,你是不是又得依次登录每个服务器再一次部署?
如果你确实是这么做的,那么你应该后悔没有早一点看到这篇文章。看完本文以后,你能够做到:
- 2 分钟内把一个新爬虫部署到 50 台服务器上:
docker build -t localhost:8003/spider:0.01 .
docker push localhost:8002/spider:0.01
docker service create --name spider --replicas 50 --network host 45.77.138.242:8003/spider:0.01
- 30 秒内把爬虫从 50 台服务器扩展到 500 台服务器:
docker service scale spider=500
- 30 秒内批量关闭所有服务器上的爬虫:
docker service scale spider=0
- 1 分钟内批量更新所有机器上的爬虫:
docker build -t localhost:8003/spider:0.02 .
docker push localhost:8003/spider:0.02
docker service update --image 45.77.138.242:8003/spider:0.02 spider
这篇文章不会教你怎么使用 Docker,所以请确定你有一些 Docker 基础再来看本文。
Docker Swarm 是什么
Docker Swarm 是 Docker 自带的一个集群管理模块。他能够实现 Docker 集群的创建和管理。
环境搭建
本文将会使用 3 台 Ubuntu 18.04 的服务器来进行演示。这三台服务器安排如下:
- Master:45.77.138.242
- Slave-1:199.247.30.74
- Slave-2:95.179.143.21
Docker Swarm 是基于 Docker 的模块,所以首先要在 3 台服务器上安装 Docker。安装完成 Docker 以后,所有的操作都在 Docker 中完成。
在 Master 上安装 Docker
通过依次执行下面的命令,在 Master 服务器上安装 Docker
apt-get update
apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
apt-get update
apt-get install -y docker-ce
创建 Manager 节点
一个 Docker Swarm 集群需要 Manager 节点。现在初始化 Master 服务器,作为集群的 Manager 节点。运行下面一条命令。
docker swarm init
运行完成以后,可以看到的返回结果下图所示。
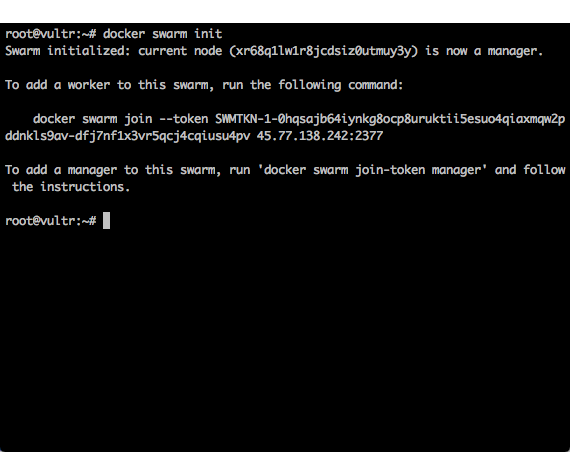
这个返回结果中,给出了一条命令:
docker swarm join --token SWMTKN-1-0hqsajb64iynkg8ocp8uruktii5esuo4qiaxmqw2pddnkls9av-dfj7nf1x3vr5qcj4cqiusu4pv 45.77.138.242:2377
这条命令需要在每一个从节点( Slave )中执行。现在先把这个命令记录下来。
初始化完成以后,得到一个只有 1 台服务器的 Docker 集群。执行如下命令:
docker node ls
可以看到当前这个集群的状态,如下图所示。

创建私有源(可选)
创建私有源并不是一个必需的操作。之所以需要私有源,是因为项目的 Docker 镜像可能会涉及到公司机密,不能上传到 DockerHub 这种公共平台。如果你的镜像可以公开上传 DockerHub,或者你已经有一个可以用的私有镜像源,那么你可以直接使用它们,跳过本小节和下一小节。
私有源本身也是一个 Docker 的镜像,先将拉取下来:
docker pull registry:latest
如下图所示。
现在启动私有源:
docker run -d -p 8003:5000 --name registry -v /tmp/registry:/tmp/registry docker.io/registry:latest
如下图所示。
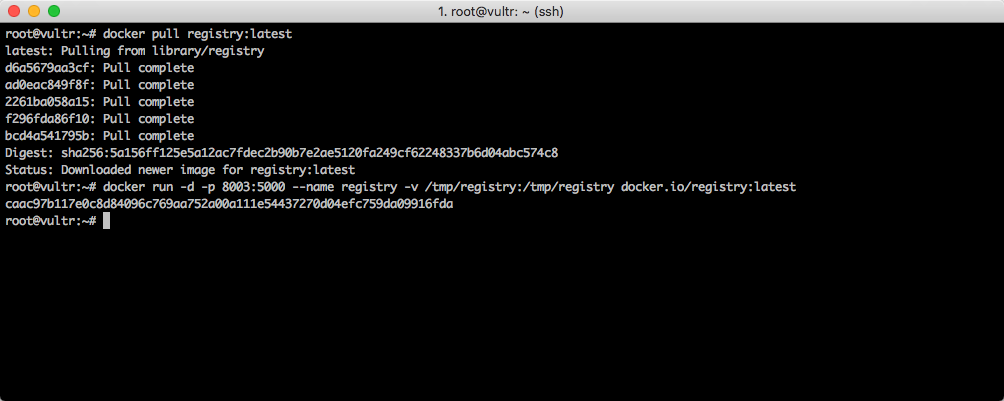
在启动命令中,设置了对外开放的端口为 8003 端口,所以私有源的地址为:45.77.138.242:8003
提示: 这样搭建的私有源是 HTTP 方式,并且没有权限验证机制,所以如果对公网开放,你需要再使用防火墙做一下 IP 白名单,从而保证数据的安全。
允许 docker 使用可信任的 http 私有源(可选)
如果你使用上面一个小节的命令搭建了自己的私有源,由于 Docker 默认是不允许使用 HTTP 方式的私有源的,因此你需要配置 Docker,让 Docker 信任它。
使用下面命令配置 Docker:
echo '{ "insecure-registries":["45.77.138.242:8003"] }' >> /etc/docker/daemon.json
然后使用下面这个命令重启 docker。
systemctl restart docker
如下图所示。

重启完成以后,Manager 节点就配置好了。
创建子节点初始化脚本
对于 Slave 服务器来说,只需要做三件事情:
- 安装 Docker
- 加入集群
- 信任源
从此以后,剩下的事情全部交给 Docker Swarm 自己管理,你再也不用 SSH 登录这个服务器了。
为了简化操作,可以写一个 shell 脚本来批量运行。在 Slave-1 和 Slave-2 服务器下创建一个init.sh文件,其内容如下。
apt-get update
apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
apt-get update
apt-get install -y docker-ce
echo '{ "insecure-registries":["45.77.138.242:8003"] }' >> /etc/docker/daemon.json
systemctl restart docker
docker swarm join --token SWMTKN-1-0hqsajb64iynkg8ocp8uruktii5esuo4qiaxmqw2pddnkls9av-dfj7nf1x3vr5qcj4cqiusu4pv 45.77.138.242:2377
把这个文件设置为可自行文件,并运行:
chmod +x init.sh
./init.sh
如下图所示。

等待脚本运行完成以后,你就可以从 Slave-1 和 Slave-2 的 SSH 上面登出了。以后也不需要再进来了。
回到 Master 服务器,执行下面的命令,来确认现在集群已经有 3 个节点了:
docker node ls
看到现在集群中已经有 3 个节点了。如下图所示。

到止为止,最复杂最麻烦的过程已经结束了。剩下的就是体验 Docker Swarm 带来的便利了。
创建测试程序
搭建测试 Redis
由于这里需要模拟一个分布式爬虫的运行效果,所以先使用 Docker 搭建一个临时的 Redis 服务:
在 Master 服务器上执行以下命令:
docker run -d --name redis -p 7891:6379 redis --requirepass "KingnameISHandSome8877"
这个 Redis 对外使用7891端口,密码为KingnameISHandSome8877,IP 就是 Master 服务器的 IP 地址。
编写测试程序
编写一个简单的 Python 程序:
import time
import redis
client = redis.Redis(host='45.77.138.242', port='7891', password='KingnameISHandSome8877')
while True:
data = client.lpop('example:swarm:spider')
if not data:
break
print(f'我现在获取的数据为:{data.decode()}')
time.sleep(10)
这个 Python 每 10 秒钟从 Redis 中读取一个数,并打印出来。
编写 Dockerfile
编写 Dockerfile,基于 Python3.6 的镜像创建我们自己的镜像:
from python:3.6
label mantainer='[email protected]'
user root
ENV PYTHONUNBUFFERED=0
ENV PYTHONIOENCODING=utf-8
run python3 -m pip install redis
copy spider.py spider.py
cmd python3 spider.py
构建镜像
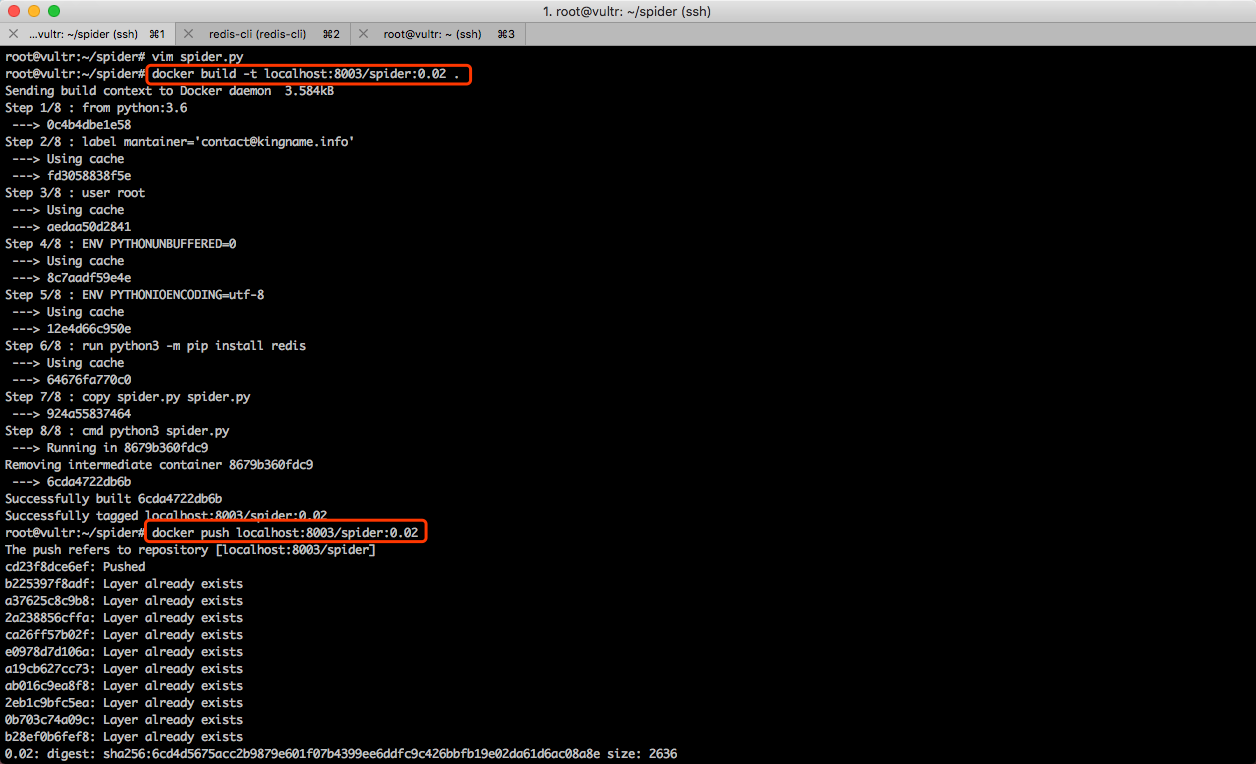
编写完成 Dockerfile 以后,执行下面的命令,开始构建我们自己的镜像:
docker build -t localhost:8003/spider:0.01 .
这里需要特别注意,由于我们要把这个镜像上传到私有源供 Slave 服务器上面的从节点下载,所以镜像的命名方式需要满足localhost:8003/自定义名字:版本号这样的格式。其中的自定义名字和版本号可以根据实际情况进行修改。在本文的例子中,我由于要模拟一个爬虫的程序,所以给它取名为 spider,由于是第 1 次构建,所以版本号用的是 0.01 。
整个过程如下图所示。
上传镜像到私有源
镜像构建完成以后,需要把它上传到私有源。此时需要执行命令:
docker push localhost:8003/spider:0.01
如下图所示。
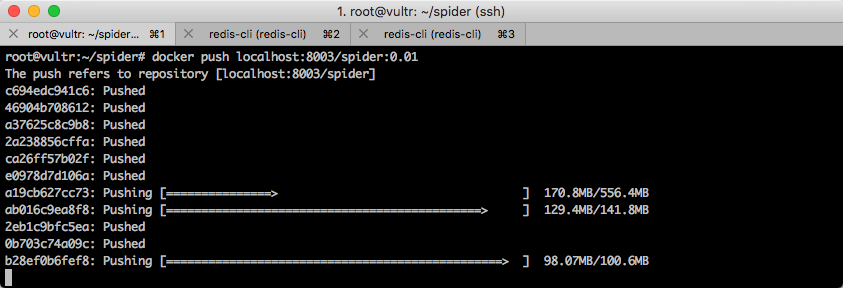
大家记住这个构建和上传的命令,以后每一次更新代码,都需要使用这两条命令。
创建服务
Docker Swarm 上面运行的是一个一个的服务,因此需要使用 docker service 命令创建服务。
docker service create --name spider --network host 45.77.138.242:8003/spider:0.01
这个命令创建了一个名为spider的服务。默认运行 1 个容器。运行情况如下图所示。

当然也可以一创建就用很多容器来运行,此时只需要添加一个--replicas参数即可。例如一创建服务就使用 50 个容器运行:
docker service create --name spider --replicas 50 --network host 45.77.138.242:8003/spider:0.01
但是一般一开始的代码可能会有不少 bug,所以建议先使用 1 个容器来运行,观察日志,发现没有问题以后再进行扩展。
回到默认 1 个容器的情况下,这个容器可能在目前三台机器在的任何一台上面。通过执行下面的命令来观察这一个默认的容器运行情况:
docker service ps spider
如下图所示。

查看节点 Log
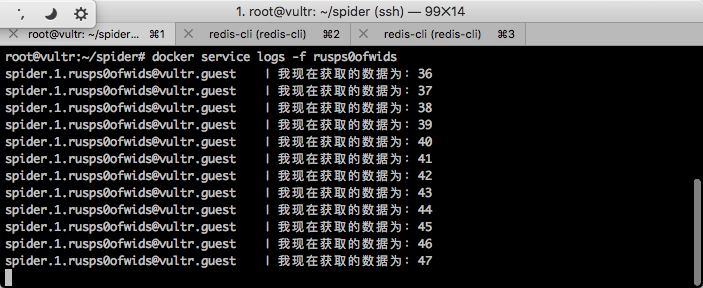
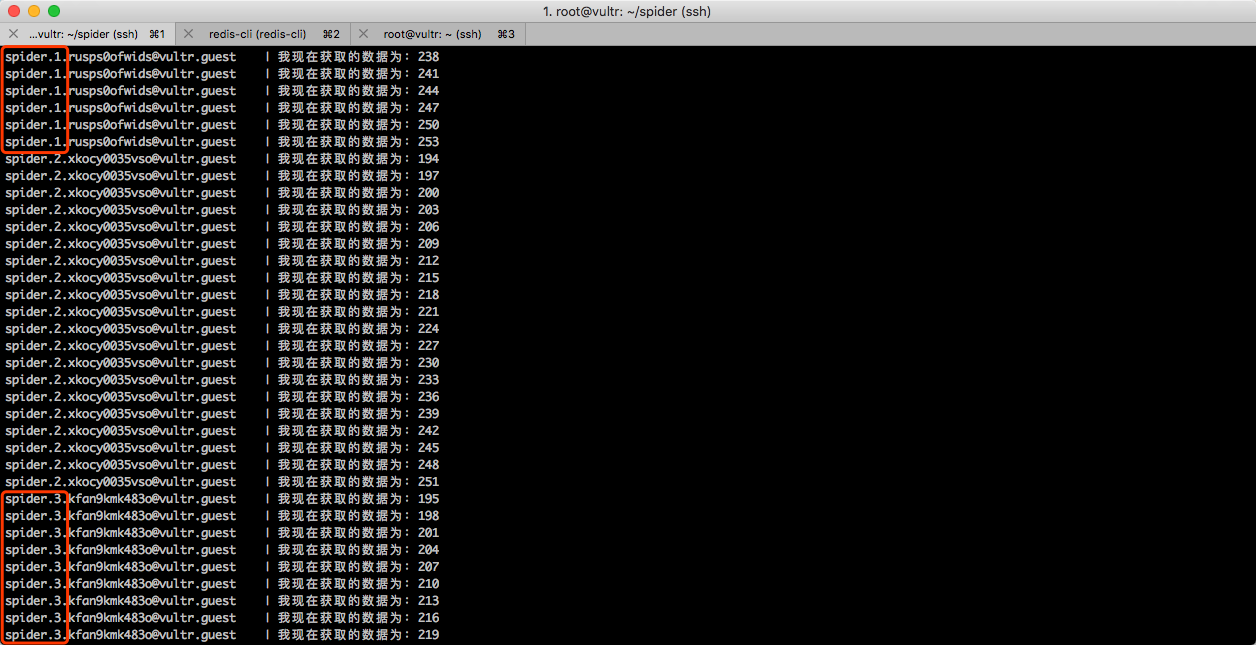
根据上图执行结果,可以看到这个运行中的容器的 ID 为rusps0ofwids,那么执行下面的命令动态查看 Log:
docker service logs -f 容器 ID
此时就会持续跟踪这一个容器的 Log。如下图所示。
横向扩展
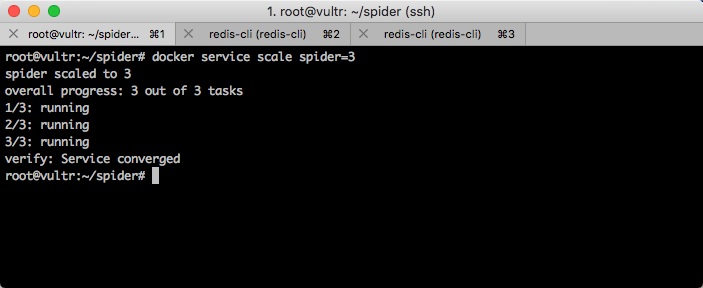
现在,只有 1 台服务器运行了一个容器,我想使用 3 台服务器运行这个爬虫,那么我需要执行一条命令即可:
docker service scale spider=3
运行效果如下图所示。
此时,再一次查看爬虫的运行情况,可以发现三台机器上面会各自运行一个容器。如下图所示。

现在,我们登录 slave-1 机器上,看看是不是真的有一个任务在运行。如下图所示。
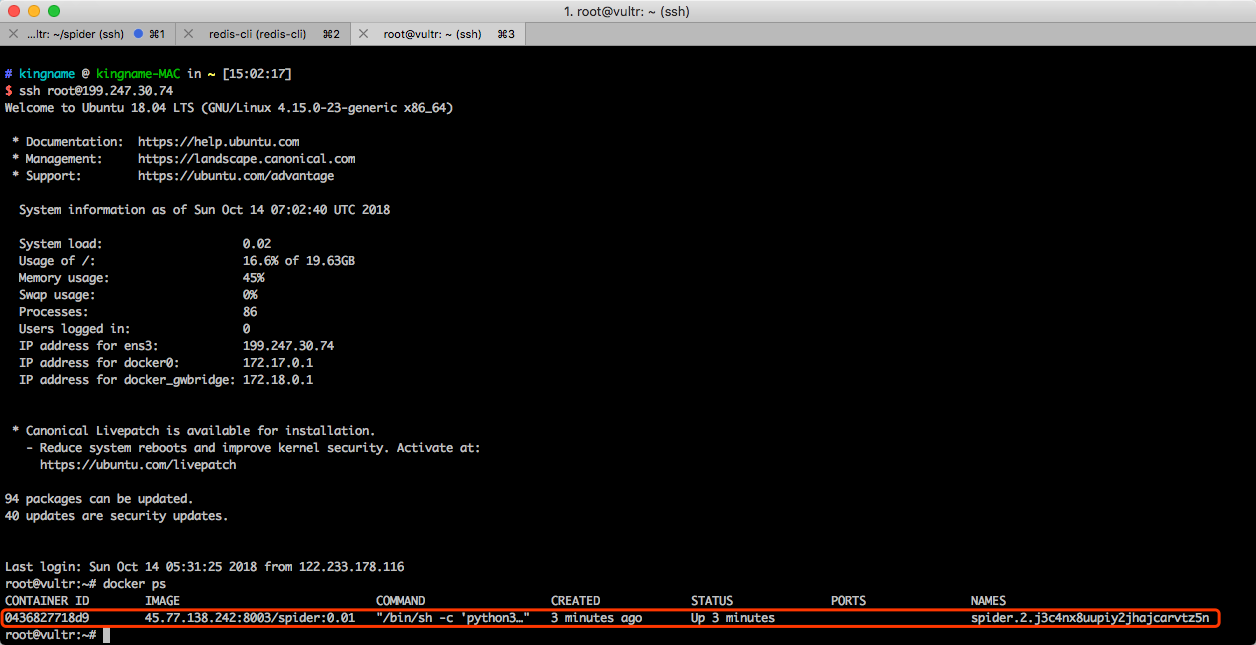
可以看到确实有一个容器在上面运行着。这是 Docker Swarm 自动分配过来的。
现在我们使用下面的命令强行把 slave-1 上面的 Docker 给关了,再来看看效果。
systemctl stop docker
回到 master 服务器,再次查看爬虫的运行效果,如下图所示。

可以看到,Docker Swarm 探测到 Slave-1 掉线以后,他就会自动重新找个机器启动任务,保证始终有 3 个任务在运行。在这一次的例子中,Docker Swarm 自动在 master 机器上启动了 2 个 spider 容器。
如果机器性能比较好,甚至可以在 3 每台机器上面多运行几个容器:
docker service scale spider=10
此时,就会启动 10 个容器来运行这些爬虫。这 10 个爬虫之间互相隔离。
如果想让所有爬虫全部停止怎么办?非常简单,一条命令:
docker service scale spider=0
这样所有爬虫就会全部停止。
同时查看多个容器的日志
如果想同时看所有容器怎么办呢?可以使用如下命令查看所有容器的最新的 20 行日志:
docker service ps robot | grep Running | awk '{print $1}' | xargs -i docker service logs --tail 20 {}
这样,日志就会按顺序显示出来了。如下图所示。
更新爬虫
如果你的代码做了修改。那么你需要更新爬虫。
先修改代码,重新构建,重新提交新的镜像到私有源中。如下图所示。
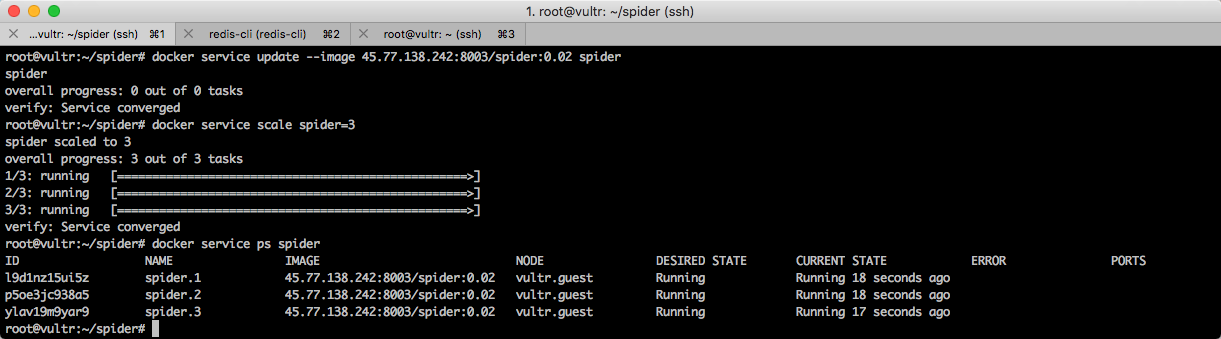
接下来需要更新服务中的镜像。更新镜像有两种做法。一种是先把所有爬虫关闭,再更新。
docker service scale spider=0
docker service update --image 45.77.138.242:8003/spider:0.02 spider
docker service scale spider=3
第二种是直接执行更新命令。
docker service update --image 45.77.138.242:8003/spider:0.02 spider
他们的区别在于,直接执行更新命令时,正在运行的容器会一个一个更新。
运行效果如下图所示。
你可以用 Docker Swarm 做更多事情
本文使用的是一个模拟爬虫的例子,但是显然,任何可以批量运行的程序都能够用 Docker Swarm 来运行,无论你用 Redis 还是 Celery 来通信,无论你是否需要通信,只要能批量运行,就能用 Docker Swarm。
在同一个 Swarm 集群里面,可以运行多个不同的服务,各个服务之间互不影响。真正做到了搭建一次 Docker Swarm 集群,然后就再也不用管了,以后的所有操作你都只需要在 Manager 节点所在的这个服务器上面运行。
广告时间
本文是多种部署分布式爬虫方法中的一种,其他方法,可以参阅我的新书《 Python 爬虫开发 从入门到实战》。现已在京东、当当、亚马逊上架。
- 京东:https://item.jd.com/12436581.html
- 当当:http://product.m.dangdang.com/25349717.html
- 亚马逊:https://www.amazon.cn/dp/B07HGBRXFW
本书读者交流群也已经开通,扫码添加公众号,回复:读者交流 即可获得加群方式。

 |
1
chengxiao 2018-10-14 17:45:05 +08:00
那请教下如何在不同的服务器上按照不同的定时频率来运行不同的爬虫呢?
|
 |
2
itskingname OP @chengxiao 很简单,每个频率各创建一个 Service,然后各做各的事情。
到启动时间了就 docker service scale xxx=100 到结束时间了就 docker service scale xxx=0 |
|
3
itskingname OP 各位收藏的 V 友,你们倒是说一句话啊,只收藏不评论就不对了。。。
|
 |
4
defunct9 2018-10-14 18:39:08 +08:00 via iPhone 爬虫、反爬虫,对抗升级,感觉好无聊
|
 |
5
zn 2018-10-14 18:44:15 +08:00
好了好了!我们都知道你有 500 台服务器了!
|
|
6
itskingname OP @defunct9 这篇文章里面,爬虫只是一个例子而已。这种方式适用于任何可以批量运行的程序
|
|
7
itskingname OP @zn 终于有一个人既收藏又评论了。
|
|
8
zn 2018-10-14 19:22:32 +08:00 via iPhone
@itskingname 你都这么说了,我不回复一下哪里对得起你,纯支持,加油吧骚年,争取财务自由!
|
 |
9
artandlol 2018-10-14 20:02:15 +08:00 via iPhone
希望搞个 k8s 版本的,毕竟 k8s 编排才是主流
|
|
10
itskingname OP @artandlol 使用 Docker Swarm,胜在它足够简单,而且不需要安装额外的东西。K8S 强大是强大,但就一个搭建环境就会逼退很多人。
|
 |
11
1747479654 2018-10-14 23:31:55 +08:00
挺详细的, 应该做自动化部署的可以用到.
|
|
12
1747479654 2018-10-14 23:33:15 +08:00 建议楼主增加个 portainer 然后管理端 endpoint 那里增加各节点的 portainer,方便以后管理 docker, 毕竟 docker 还没到大规模应用阶段,一般大家只能拿来做测试,和临时项目.
|
 |
13
Vogan 2018-10-14 23:58:28 +08:00
这篇文章不会教你怎么使用 Docker,但是会教你怎么使用 docker service
|
|
14
itskingname OP 感谢建议。portainer 正是我第二篇文章将会介绍到的东西~。
|
|
15
itskingname OP @Vogan 哈哈哈
|
 |
16
YzSama 2018-10-15 01:07:08 +08:00 via iPhone
集群的日志在 docker swarm 里面好像没这么方便。服务编排的主要问题是 日志、监控等吧。k8s 有现成的方案。
|
|
17
artandlol 2018-10-15 08:35:51 +08:00
@itskingname 那是以前 现在 k8s 已经没那么难了
实在不行你用 rancher2.0 搭一个也行 https://www.cnrancher.com/docs/rancher/v2.x/cn/overview/quick-start-guide/ |
 |
18
sparkssssssss 2018-10-15 09:48:27 +08:00
收藏了,希望能更多干货,谢谢
|
|
19
itskingname OP 收藏 41,评论才 18 ?
|
|
20
itskingname OP @YzSama 其实可以使用管道,在主控的那个节点上把所有的日志都导出来,再通过 Filebeat 传进 Logstash
|
|
21
itskingname OP @coolloves 公众号上面每天都会更新干货。
|
|
22
itskingname OP @artandlol 我觉得还是需要分场景。不能因为 K8S 高级就什么事情都用 K8S。Docker Swarm 在某些方面确实不如 K8S,但是只安装 Docker 就能用,也足够简单。
|
|
23
YzSama 2018-10-15 10:31:53 +08:00
@itskingname #22 Docker Swarm 在网络这块问题比较大,overlay 性能比较弱。
|
|
24
itskingname OP @YzSama 我一般都是--network host
|
 |
25
ddup 2018-10-15 11:53:58 +08:00
收藏备用 感谢爬虫大佬
|
 |
26
toinmyfree 2018-10-15 17:36:00 +08:00
好了,问题来了,一开始是谁在 500 台机器上安装 docker 的呢,[:doger]
|
|
27
itskingname OP @toinmyfree 以 Google compute platform 为例,可以设置创建实例以后自动运行的代码。把安装和配置的 shell 命令写进去即可。这样利用实例模板批量创建实例以后,一次都不需要登录。
|
 |
28
sean233 2018-10-16 18:27:58 +08:00
先收藏,然后去学习下 docker 再来看。
|
 |
29
akmonde 2018-10-16 23:42:31 +08:00
书不错,不过感觉讲的比较基础,楼主有计划出进阶版本吗?
|
|
30
itskingname OP @akmonde 嗯。
|
 |
31
gamesover 2019-11-19 07:58:23 +08:00
哇,这正是我想问的问题。我网上看到的教程 docker swarm 集群都是有内网机器组成的,就是不知道几台分散的公网机器能不能组成 swarm。请问 k8s 能不能也同样由几台分散的公网机器组成集群啊?
|
|
32
itskingname OP @gamesover 可以。
|
|
33
gamesover 2019-11-19 09:41:46 +08:00
@itskingname 感谢大佬答复。可惜 k8s 对机器要求较高,好像最低配置要 2cpu,2G 内存起步,至少对 master ?好像 slave node 要求可以低一点。我薅羊毛薅来的 server 都是东一台西一台,也没有一台内存超过 1g。能不能内网机器做 master,公网机器做 slave ?
|
|
34
itskingname OP @gamesover 只要 slave 能连上 master,就可以。
|