 PageSpeed 相关文档
› 为 NGINX 编译 PageSpeed 支持
› ngx_pagespeed
› Configuring mod_pagespeed Filters
加载性能测试工具
› WebPagetest
› Gomez
PageSpeed 相关文档
› 为 NGINX 编译 PageSpeed 支持
› ngx_pagespeed
› Configuring mod_pagespeed Filters
加载性能测试工具
› WebPagetest
› Gomez

这是一个创建于 2905 天前的主题,其中的信息可能已经有所发展或是发生改变。
目前大家使用最多也是最广泛的应用打包工具就是 webpack 了,除去 webpack 本身已经提供的优化能力(例如,Tree Shaking、Code Splitting 等)之外,我们还能做哪些事情呢,本篇主要就为大家介绍下滴滴 WebApp 团队在这条路上的一些探索。
前言
现在越来越多的项目都使用 ES2015+ 开发,并且搭配 webpack + babel 作为工程化基础,并通过 NPM 去加载第三方依赖库。同时为了达到代码复用的目的,我们会把一些自己开发的组件库或者是 JSSDK 抽成独立的仓库维护,并通过 NPM 去加载。
大部分人已经习惯了这样的开发方式,并且觉得非常方便实用。但在方便的背后,却隐藏了两个问题:
-
代码冗余
一般来说,这些 NPM 包也是基于 ES2015+ 开发的,每个包都需要经过 babel 编译发布后才能被主应用使用,而这个编译过程往往会附加很多“编译代码”;每个包都会有一些相同的编译代码,这就造成大量代码的冗余,并且这部分冗余代码是不能通过 Tree Shaking 等技术去除掉的。
-
非必要的依赖
考虑到组件库的场景,通常我们为了方便一股脑引入了所有组件;但实际情况下对于一个应用而言可能只是用到了部分组件,此时如果全部引入,也会造成代码冗余。
代码的冗余会造成静态资源包加载时间变长、执行时间也会变长,进而很直接的影响性能和体验。既然我们已经认识到有此类问题,那么接下来看看如何解决这两个问题。
核心
我们对于上述的 2 个问题,核心的解决优化方案是:后编译和按需引入。
效果
先来看下滴滴车票项目(用票人)优化前后的数据(非 gzip,压缩后整个项目的大小):
- 普通打包:455 KB
- 后编译:423 KB
- 后编译 & 按需引入:388 KB
- 后编译 & 按需引入 & babel-preset-env:377 KB
最终减少了约 80 KB,优化效果还是相当可观的。
上边的数据主要是对组件库和一些内部通用 JSSDK 采用后编译和按需引入策略后的效果,需要注意的是按需引入的效果是要视项目情况而定的,这里的数据仅供参考。
下面就分别来看看这两个点的具体细节。
后编译
先来解释下:
后编译:指的是应用依赖的 NPM 包并不需要在发布前编译,而是随着应用编译打包的时候一块编译。
后编译的核心在于把编译依赖包的时机延后,并且统一编译;先来看看它的 webpack 配置。
配置
对具体项目应用而言,做到后编译,其实不需要做太多,只需要在 webpack 的配置文件中,包含需要我们去后编译的依赖包即可( webpack 2+):
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
// ...
{
test: /\.js$/,
loader: 'babel-loader',
// 注意这里的 include
// 除了 src 还包含了额外的 node_modules 下的两个包
include: [
resolve('src'),
resolve('node_modules/A'),
resolve('node_modules/B')
]
},
// ...
]
},
// ...
}
我们只需要把后编译的模块 A 和 B 通过 webpack 的 include 配置包含进来即可。
但是这里会存在一些问题,举个例子,如下图:
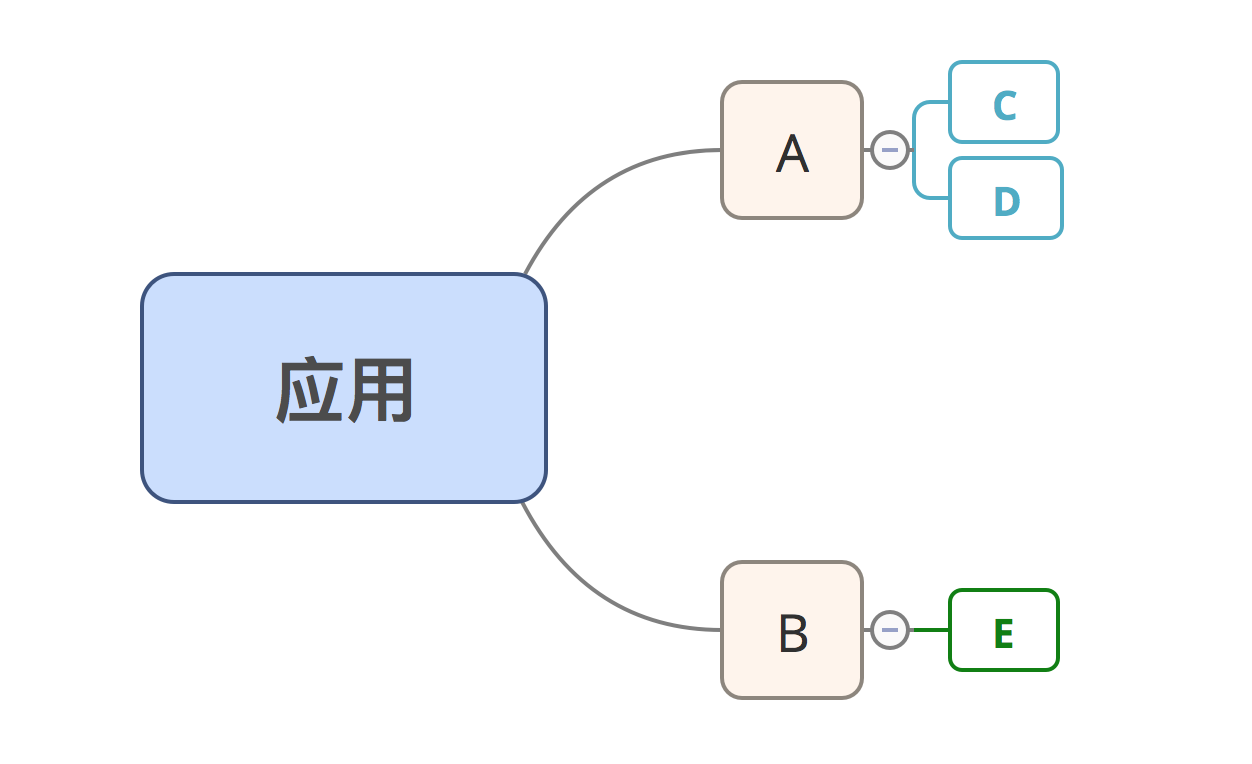
上述所示的应用中依赖了需要后编译的包 A 和 B,而 A 又依赖了需要后编译的包 C 和 D,B 依赖了不需要后编译的包 E ;重点来看依赖包 A 的情况:A 本身需要后编译,然后 A 的依赖包 C 和 D 也需要后编译,这种场景我们可以称之为嵌套后编译,此时如果依旧通过上边的 webpack 配置方式的话,还必须要显示的去 include 包 C 和 D,但对于应用而言,它只知道自身需要后编译的包 A 和 B,并不知道 A 也会有需要后编译的包 C 和 D,所以应用不应该显示的去 include 包 C 和 D,而是应该由 A 显示的去声明自己需要哪些后编译模块。
为了解决上述嵌套后编译问题,我们开发了一个 webpack 插件 webpack-post-compile-plugin,用于自动收集后编译的依赖包以及其嵌套依赖;来看下这个插件的核心代码:
var util = require('./util')
function PostCompilePlugin (options) {
// ...
}
PostCompilePlugin.prototype.apply = function (compiler) {
var that = this
compiler.plugin(['before-run', 'watch-run'], function (compiler, callback) {
// ...
var dependencies = that._collectCompileDependencies(compiler)
if (dependencies.length) {
var rules = compiler.options.module.rules
rules && rules.forEach(function (rule) {
if (rule.include) {
if (!Array.isArray(rule.include)) {
rule.include = [rule.include]
}
rule.include = rule.include.concat(dependencies)
}
})
}
callback()
})
}
原理就是在 webpack compiler 的 before-run 和 watch-run 事件钩子中去收集依赖然后附加到 webpack module.rule 的 include 上;收集的规则就是查找应用或者依赖包的 package.json 中声明的 compileDependencies 作为后编译依赖。
所以对于上述应用的情况,使用 webpack-post-compile-plugin 插件的 webpack 配置:
var PostCompilePlugin = require('webpack-post-compile-plugin')
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
// ...
{
test: /\.js$/,
loader: 'babel-loader',
include: [
resolve('src')
]
},
// ...
]
},
// ...
plugins: [
new PostCompilePlugin()
]
}
当前项目的 package.json 中添加 compileDependencies 字段来指定后编译依赖包:
// app package.json
{
// ...
"compileDependencies": ["A", "B"]
// ...
}
A 还有后编译依赖,所以需要在包 A 的 package.json 中指定 compileDependencies:
// A package.json
{
// ...
"compileDependencies": ["C", "D"]
// ...
}
优点
- 公共的依赖可以实现共用,只此一份,重要的是只编译一次,建议通过 peerDependencies 管理依赖。
- babel 转换 API (例如 babel-plugin-transform-runtime 或者 babel-polyfill )部分的代码只有一份。
- 不用每个依赖包都需要配置编译打包环节,甚至可以直接源码级别发布。
PS: 关于 babel-plugin-transform-runtime 和 babel-polyfill 的选择问题,对于应用而言,我们建议的是采用 babel-polyfill。因为一些第三方包的依赖会判断全局是否支持某些特性,而不去做 polyfill 处理。例如:vuex 会检查是否支持 Promise,如果不支持则会报错;或者说在代码中有类似 "foobar".includes("foo") 的代码的话 babel-plugin-transform-runtime 也是不能正确处理的。
当然,后编译的技术方案肯定不是完美无瑕的,它也会有一些缺点。
缺点
- 主应用的 babel 配置需要能兼容依赖包的 babel 配置。
- 依赖包不能使用 alias、不能方便的使用 DefinePlugin (可以经过一次简单编译,但是不做 babel 处理)。
- 应用编译时间会变长。
虽然有一些缺点,但是综合考虑到成本 /收益,目前来看采用后编译仍不失为一种不错的选择。
按需引入
后编译主要解决的问题是代码冗余,而按需引入主要是用来解决非必要的依赖的问题。
按需引入针对的场景主要是组件库、工具类依赖包。因为不管是组件库还是依赖包,往往都是“大而全”的,而在开发应用的时候,我们可能只是使用了其一部分能力,如果全部引入的话,会有很多资源浪费。
为了解决这个问题,我们需要按需引入。目前主流组件库或者工具包也都是提供按需引入能力的,但是基本都是提供对编译后模块引入。
而我们推荐的是对源码的按需引入,配合后编译的打包方案 。
但是实际上我们可能会遇到一些向后兼容问题,不能一竿子打死,例如之前已经创建的项目,目前没有人力或者时间去做对应的升级改造,那么我们对内的一些组件库或者工具包目前需要做一点牺牲:提供两个入口,一个编译后的入口,一个源码入口。
入口之争
这里涉及到一个 NPM 包有两个入口的问题,不过还好这个问题 webpack 2+ 或者 rollup 已经帮我们处理了,即编译后入口依旧使用 package.json 中的 main 字段,然后源码的入口使用 module 字段,可以参见 rollup pkg.module wiki。这样我们就能实现两个入口共享,既能保证向后兼容,又可以保证使用 webpack 2+ 或者 rollup 的入口直接指向的就是源码,在这样的基础上可以很直接的利用后编译了。
Vue 组件库编译
后编译和按需引入一个最最典型的场景就是我们的组件库,这里分享下我们对于组件库(基于 Vue )的实践经验。
按需引入,在没有后编译的时候,其实我们已经实现了在编译发布的时候直接做到自动根据各模块分别编译,这样使用方就可以直接引入对应目录的入口文件。这个原理很简单:遍历源码目录下的模块目录,得到各个入口,动态修改了组件库 webpack 配置的入口。而这个过程在__后编译__场景中就不存在了,可以直接引入到源码所对应的模块入口,因为后编译不需要依赖包自己编译,只需要应用去编译就好了。
对于组件而言,如果是前编译的话,一般我们会编译出入口 JS 文件,以及样式 CSS 文件,这样如果来实现按需引入的话,可能是这样的:
import Dialog from 'cube-ui/lib/dialog'
import 'cube-ui/lib/dialog/style.css'
即使是在后编译场景下,虽然不需要处理样式问题了,但是还是会遇到按需引入的时候,路径不够优雅:
import Dialog from 'cube-ui/src/modules/dialog'
以上不管是哪种,总是不够优雅,幸好有一个 babel 插件 babel-plugin-transform-imports 来帮助我们优雅的按需引入。但是对于我们编译后的场景,还需要引入样式,为此,我们对其做了统一,在 babel-plugin-transform-imports 上做了增强的 babel-plugin-transform-modules 插件,增设了 style 配置项。
所以不管是不是使用了后编译,我们想要做到按需引入,只需要:
import { Dialog } form 'cube-ui'
这样写就可以了,如果你是使用的后编译,直接引入的是源码,那么只需要在 .babelrc 文件中增加如下配置:
"plugins": [
["transform-modules", {
"cube-ui": {
"transform": "cube-ui/src/modules/${member}",
"preventFullImport": true,
"kebabCase": true
}
}]
]
而如果是 webpack 1 或者说使用的组件库是已经编译后的,那只需要增设 style 配置项即可:
"plugins": [
["transform-modules", {
"cube-ui": {
"transform": "cube-ui/lib/${member}",
"preventFullImport": true,
"kebabCase": true,
"style": true
}
}]
]
这样我们就通过一个插件实现了优雅的按需引入,不管是不是使用了后编译,对于开发者而言只需要修改下 babel 的配置即可,而不需要大肆去修改源码中的引入路径。
总结
以上就是我们基于 webpack 的编译优化的一点探索,这里可以总结下使用 webpack 做应用编译打包的“最佳实践”:
后编译 + 按需引入
再搭配上 babel-preset-env, babel-plugin-transform-modules 开发体验以及收益效果更好。
 |
1
rashawn 2017-10-10 12:29:50 +08:00 via iPhone
其实按需引入完全可以需要的时候发个请求下载下来 new 个 blob 用,编译就每部分单独编译,编译速度还快很多
|