
这是一个创建于 3055 天前的主题,其中的信息可能已经有所发展或是发生改变。
作为推送行业领导者,截止目前个推 SDK 累计安装覆盖量达 100 亿(含海外),接入应用超过 43 万,独立终端覆盖超过 10 亿 (含海外)。个推系统每天会产生大量的日志和数据,面临许多数据处理方面的挑战。
首先数据存储方面,个推每天产生 10TB 以上的数据,并且累积数据已在 PB 级别。其次,作为推送技术服务商,个推有很多来自客户和公司各部门的数据分析和统计需求,例如:消息推送和数据报表。虽然部分数据分析工作是离线模式,但开源数据处理系统稳定性并不很高,保障数据分析服务的高可用性也是一个挑战。另外,推送业务并不是单纯的消息下发,它需帮助客户通过数据分析把合适的内容在合适的场景送达给合适的人,这要求系统支持数据挖掘,并保证数据实时性。最后,个推要求快速响应数据分析需求。因此,个推大数据系统面临着数据存储、日志传输、日志分析处理、大量任务调度和管理、数据分析处理服务高可用、海量多维度报表和快速响应分析和取数需求等方面的挑战。
大数据系统演进之路
面临诸多挑战,个推大数据系统在逐步发展中不断完善。其发展可分为三个阶段。一是统计报表,即传统意义的 BI ;二是大数据系统的基础建设阶段;三是工具、服务和产品化。
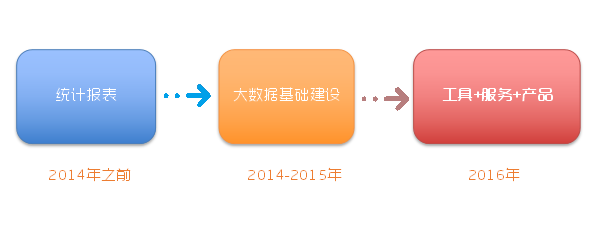
个推大数据系统演进第一阶段:统计报表计算
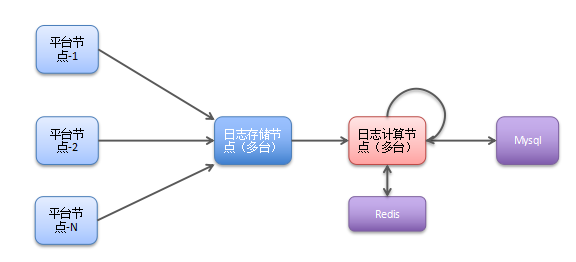
早期由于数据处理无太复杂的需求,个推选择几台高性能的机器,把所有数据分别放在这些机器上计算。只需在机器上多进程运行 PHP 或 Shell 脚本即可完成处理和统计。数据处理更多关注客户今天推送多少条消息,某个推送任务有多少回执等,执行相对较简单的报表。
此阶段个推大数据系统的特点是,只需运维定时脚本传输到指定中间节点;用户虽然有亿级别但日志种类较单一;只需使用 PHP 、 Shell 脚本来运行和数据只需短期保存(结果集长期保存、中间数据和原始数据保存很短时间)。
个推大数据系统演进第二阶段:大数据基础建设,离线批处理系统
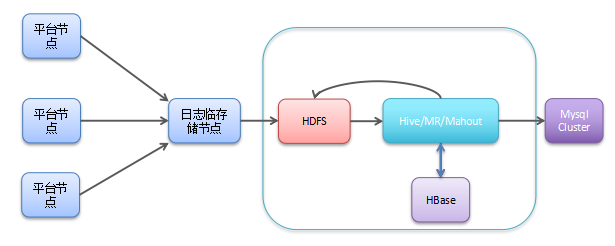
2014 年个推推出智能推送解决方案。用户体量大的明星 App 接入,系统覆盖用户数爆增。且客户接入个推系统后,提出了很多新的需求如:报表统计维度更丰富,它要求在数据量翻倍的情况下进行更复杂的计算,计算压力增大。其次,智能推送本质是数据深度挖掘,数据保存周期越长,覆盖维度越多越好。
这样的情况下,个推引进 Hadoop 生态体系,用 HDFS 基本解决存储的问题,使用 Hive 做数据仓库和离线分析,并且使用 Mahout 做机器学习。个推完成了由单机或多机模式向集群方向的转变。整个运转流程和原来类似,差别在于将日志传输到中转节点之后,使用 hdfs 命令 put 数据到 hdfs ,并添加 hive 表分区,然后对日志做进一步的处理,导入到数据仓储里去。最后个推对数据仓库中数据进行挖掘,给用户打标签,入库到 HBase 和线上 ES 等。这是离线批处理系统的基本建设。
个推大数据系统演进第二阶段:大数据基础建设,实时处理系统
随着业务不断发展,需求也相应增加。如很多统计分析任务提出了要求在 T+0 的时间内满足,或者客户上午推送的消息,下午要求给到反映推送效果的数据报表,而不能等到 T+1 的时间,这些需求都对数据处理实时性提出了更高要求。而且很多客户会提出要检索一些数据,或查看某种标签相关数据,这类取数需要快速响应。于是个推对原有的架构进行了一些调整,引入了一个主要包含离线处理、实时处理和数据服务(包含检索)的架构模式。
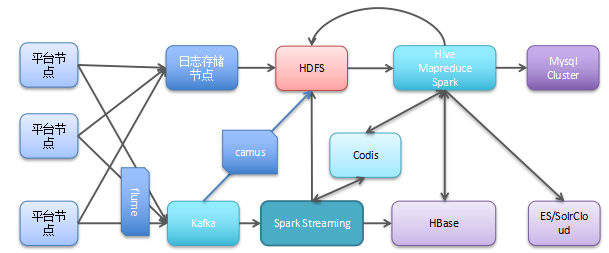
从上方看,原有的数据存到 HDFS ,使用 Spark , MR 等进行离线批处理。引入 Kafka 来解决日志收集问题,用 Flume 收集各个业务节点的日志,并写入到 Kafka 集群,再依照业务的分级进行小时级别和秒级别处理。最终个推会落地一份数据,将它同步给业务线的 DB 或 ES 中使用。
基础建设阶段个推完成几项工作:采用 Lambda 架构( Batch Layer 、 Speed Layer 、 ServingLayer );引入 Hadoop ( Hdfs 、 Hive/MR 、 Hbase 、 Mahout 等);采用 ES 、 SolrCloud+ HBase 方案 实现多维度检索;引入 Flume 、 Kafka 、 Camus 和优化改造日志传输和引入和优化国产开源的 Redis 集群方案-Codis 。
个推大数据系统演进第三阶段:工具化+服务化+产品化
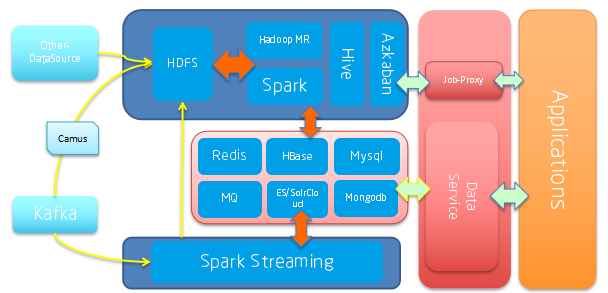
基础建设过程中,个推发现虽有了整体框架,但依然不能比较便捷地响应业务方的需求。所以个推选择提供工具给业务方,并增加一个服务代理层,也就是上图红色部分,把批处理任务等抽象成任务模板,配置到代理层,最终提给业务方调用,他们只要做简单的二次开发,就可以使用个推集群的计算服务,提高业务开发速度。
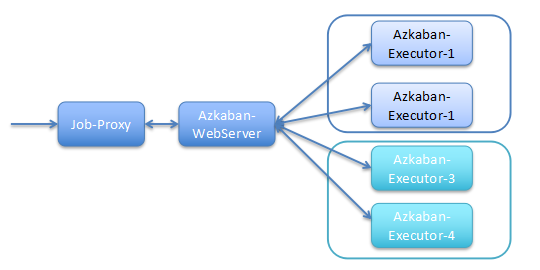
这个阶段,个推在架构上主要完成了以下工作:增加 Job 调度管理:引入 Azkaban 和进行改造(变量共享、多集群支持等);增加服务代理层:引入 DataService 和 Job Proxy(开放给更多产品线使用并解耦);增加应用层:基于服务代理层研发相应的工具和取数产品。
个推大数据系统演进的经验与总结
第一,探索数据和理解数据是开发前必备工作。数据处理之前需要探索有哪些脏数据,这些脏数据的分布,以及无效数据和缺省情况的发现等。
第二,数据存储方案向分析和计算需要靠拢。可以考虑使用类似 Carbondata 等带有索引的文件格式。
第三,数据标准化是提高后续处理首要手段。绝大部分数据需要标准化后供给后续使用(基本清洗、统一内部 ID 、增加必备属性),如对实时性数据,应先做标准化处理后,再发布到 Kafka 里,最后供所有其他实时系统做处理,减少常规清洗和转化处理在多个业务中重复做,并且统一 ID ,便于和数据打通。
第四,工具化、服务化、产品化提高整体效率。在开发层面可以将 MR 、 Spark 进行 API 封装并且提供足够的工具包。
第五,大数据系统全链路监控很重要。批处理监控主要包括:日常任务运行时间监控、是否出现倾斜、结果集每日曲线、异常数据曲线, GC 监控;流式处理监控包括:原数据波动监控、消费速率监控报警、计算节点 delay 监控等。
首先数据存储方面,个推每天产生 10TB 以上的数据,并且累积数据已在 PB 级别。其次,作为推送技术服务商,个推有很多来自客户和公司各部门的数据分析和统计需求,例如:消息推送和数据报表。虽然部分数据分析工作是离线模式,但开源数据处理系统稳定性并不很高,保障数据分析服务的高可用性也是一个挑战。另外,推送业务并不是单纯的消息下发,它需帮助客户通过数据分析把合适的内容在合适的场景送达给合适的人,这要求系统支持数据挖掘,并保证数据实时性。最后,个推要求快速响应数据分析需求。因此,个推大数据系统面临着数据存储、日志传输、日志分析处理、大量任务调度和管理、数据分析处理服务高可用、海量多维度报表和快速响应分析和取数需求等方面的挑战。
大数据系统演进之路
面临诸多挑战,个推大数据系统在逐步发展中不断完善。其发展可分为三个阶段。一是统计报表,即传统意义的 BI ;二是大数据系统的基础建设阶段;三是工具、服务和产品化。

个推大数据系统演进第一阶段:统计报表计算

早期由于数据处理无太复杂的需求,个推选择几台高性能的机器,把所有数据分别放在这些机器上计算。只需在机器上多进程运行 PHP 或 Shell 脚本即可完成处理和统计。数据处理更多关注客户今天推送多少条消息,某个推送任务有多少回执等,执行相对较简单的报表。
此阶段个推大数据系统的特点是,只需运维定时脚本传输到指定中间节点;用户虽然有亿级别但日志种类较单一;只需使用 PHP 、 Shell 脚本来运行和数据只需短期保存(结果集长期保存、中间数据和原始数据保存很短时间)。
个推大数据系统演进第二阶段:大数据基础建设,离线批处理系统

2014 年个推推出智能推送解决方案。用户体量大的明星 App 接入,系统覆盖用户数爆增。且客户接入个推系统后,提出了很多新的需求如:报表统计维度更丰富,它要求在数据量翻倍的情况下进行更复杂的计算,计算压力增大。其次,智能推送本质是数据深度挖掘,数据保存周期越长,覆盖维度越多越好。
这样的情况下,个推引进 Hadoop 生态体系,用 HDFS 基本解决存储的问题,使用 Hive 做数据仓库和离线分析,并且使用 Mahout 做机器学习。个推完成了由单机或多机模式向集群方向的转变。整个运转流程和原来类似,差别在于将日志传输到中转节点之后,使用 hdfs 命令 put 数据到 hdfs ,并添加 hive 表分区,然后对日志做进一步的处理,导入到数据仓储里去。最后个推对数据仓库中数据进行挖掘,给用户打标签,入库到 HBase 和线上 ES 等。这是离线批处理系统的基本建设。
个推大数据系统演进第二阶段:大数据基础建设,实时处理系统
随着业务不断发展,需求也相应增加。如很多统计分析任务提出了要求在 T+0 的时间内满足,或者客户上午推送的消息,下午要求给到反映推送效果的数据报表,而不能等到 T+1 的时间,这些需求都对数据处理实时性提出了更高要求。而且很多客户会提出要检索一些数据,或查看某种标签相关数据,这类取数需要快速响应。于是个推对原有的架构进行了一些调整,引入了一个主要包含离线处理、实时处理和数据服务(包含检索)的架构模式。

从上方看,原有的数据存到 HDFS ,使用 Spark , MR 等进行离线批处理。引入 Kafka 来解决日志收集问题,用 Flume 收集各个业务节点的日志,并写入到 Kafka 集群,再依照业务的分级进行小时级别和秒级别处理。最终个推会落地一份数据,将它同步给业务线的 DB 或 ES 中使用。
基础建设阶段个推完成几项工作:采用 Lambda 架构( Batch Layer 、 Speed Layer 、 ServingLayer );引入 Hadoop ( Hdfs 、 Hive/MR 、 Hbase 、 Mahout 等);采用 ES 、 SolrCloud+ HBase 方案 实现多维度检索;引入 Flume 、 Kafka 、 Camus 和优化改造日志传输和引入和优化国产开源的 Redis 集群方案-Codis 。
个推大数据系统演进第三阶段:工具化+服务化+产品化

基础建设过程中,个推发现虽有了整体框架,但依然不能比较便捷地响应业务方的需求。所以个推选择提供工具给业务方,并增加一个服务代理层,也就是上图红色部分,把批处理任务等抽象成任务模板,配置到代理层,最终提给业务方调用,他们只要做简单的二次开发,就可以使用个推集群的计算服务,提高业务开发速度。
这个阶段,个推在架构上主要完成了以下工作:增加 Job 调度管理:引入 Azkaban 和进行改造(变量共享、多集群支持等);增加服务代理层:引入 DataService 和 Job Proxy(开放给更多产品线使用并解耦);增加应用层:基于服务代理层研发相应的工具和取数产品。

个推大数据系统演进的经验与总结
第一,探索数据和理解数据是开发前必备工作。数据处理之前需要探索有哪些脏数据,这些脏数据的分布,以及无效数据和缺省情况的发现等。
第二,数据存储方案向分析和计算需要靠拢。可以考虑使用类似 Carbondata 等带有索引的文件格式。
第三,数据标准化是提高后续处理首要手段。绝大部分数据需要标准化后供给后续使用(基本清洗、统一内部 ID 、增加必备属性),如对实时性数据,应先做标准化处理后,再发布到 Kafka 里,最后供所有其他实时系统做处理,减少常规清洗和转化处理在多个业务中重复做,并且统一 ID ,便于和数据打通。
第四,工具化、服务化、产品化提高整体效率。在开发层面可以将 MR 、 Spark 进行 API 封装并且提供足够的工具包。
第五,大数据系统全链路监控很重要。批处理监控主要包括:日常任务运行时间监控、是否出现倾斜、结果集每日曲线、异常数据曲线, GC 监控;流式处理监控包括:原数据波动监控、消费速率监控报警、计算节点 delay 监控等。
1
icemanpro 2016-08-08 16:21:23 +08:00
先解决浏览器版的推送吧。
|
