推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

背景
这两天构思了一个爬虫框架,对外提供 API 创建爬虫任务,然后内部的队列会进行爬虫的消费。只需要实现数据的解析接口就能快速编写爬虫。非常适合需要利用 AI 快速生成爬虫代码的团队。
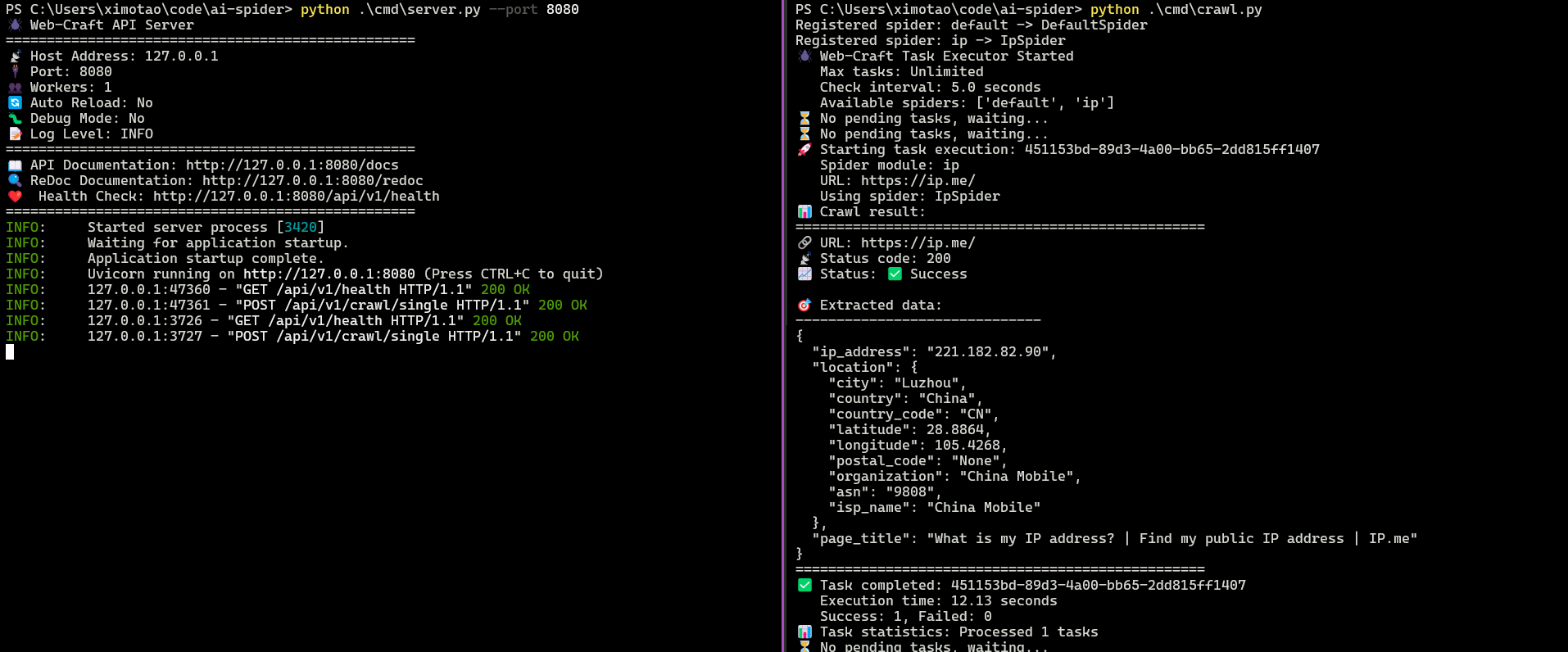
这个框架对外提供了 API 接口来创建,非常便利。目前的设计思路就是只需要实现一个 parse 接口,就行了,方便后续 AI 的介入。
后续开发计划
- 开放 AI 接口,通过 AI 自动生成爬虫代码
- 集成基于 redis 的任务队列
- 实现对外输出的接口层,例如爬虫结果转储到 mysql 等。
目前这是一个非常简单清晰的项目,希望和感兴趣的朋友共建这个项目,提升大家的技术影响力,或许对找远程工作也是有帮助的。
 |
1
BingoW 1 小时 56 分钟前
scrapy:我算什么
|
 |
2
happytaoer OP @BingoW 比 scrapy 还轻量。大部分爬虫只需要实现 parse 方法即可得到支持 API 的爬虫系统。并且对 AI 编写爬虫特别友好。未来的开发思路是精简为主,完成核心功能,提供 AI 快速集成。
from typing import Dict, Any from ..core.base_spider import BaseSpider class DefaultSpider(BaseSpider): def parse(self, raw_content: str, url: str, headers: Dict[str, str]) -> Dict[str, Any]: return raw_content |