
这是一个创建于 1458 天前的主题,其中的信息可能已经有所发展或是发生改变。
摘要:本文所介绍 Nebula Graph 连接器 Nebula Flink Connector,采用类似 Flink 提供的 Flink Connector 形式,支持 Flink 读写分布式图数据库 Nebula Graph 。
文章首发 Nebula Graph 官网博客:https://nebula-graph.com.cn/posts/nebula-flink-connector/

在关系网络分析、关系建模、实时推荐等场景中应用图数据库作为后台数据支撑已相对普及,且部分应用场景对图数据的实时性要求较高,如推荐系统、搜索引擎。为了提升数据的实时性,业界广泛应用流式计算对更新的数据进行增量实时处理。为了支持对图数据的流式计算,Nebula Graph 团队开发了 Nebula Flink Connector,支持利用 Flink 进行 Nebula Graph 图数据的流式处理和计算。
Flink 是新一代流批统一的计算引擎,它从不同的第三方存储引擎中读取数据,并进行处理,再写入另外的存储引擎中。Flink Connector 的作用就相当于一个连接器,连接 Flink 计算引擎跟外界存储系统。
与外界进行数据交换时,Flink 支持以下 4 种方式:
- Flink 源码内部预定义 Source 和 Sink 的 API ;
- Flink 内部提供了 Bundled Connectors,如 JDBC Connector 。
- Apache Bahir 项目中提供连接器 Apache Bahir 最初是从 Apache Spark 中独立出来的项目,以提供不限于 Spark 相关的扩展 /插件、连接器和其他可插入组件的实现。
- 通过异步 I/O 方式。
流计算中经常需要与外部存储系统交互,比如需要关联 MySQL 中的某个表。一般来说,如果用同步 I/O 的方式,会造成系统中出现大的等待时间,影响吞吐和延迟。异步 I/O 则可以并发处理多个请求,提高吞吐,减少延迟。
本文所介绍 Nebula Graph 连接器 Nebula Flink Connector,采用类似 Flink 提供的 Flink Connector 形式,支持 Flink 读写分布式图数据库 Nebula Graph 。
一、Connector Source
Flink 作为一款流式计算框架,它可处理有界数据,也可处理无界数据。所谓无界,即源源不断的数据,不会有终止,实时流处理所处理的数据便是无界数据;批处理的数据,即有界数据。而 Source 便是 Flink 处理数据的数据来源。
Nebula Flink Connector 中的 Source 便是图数据库 Nebula Graph 。Flink 提供了丰富的 Connector 组件允许用户自定义数据源来连接外部数据存储系统。
1.1 Source 简介
Flink 的 Source 主要负责外部数据源的接入,Flink 的 Source 能力主要是通过 read 相关的 API 和 addSource 方法这 2 种方式来实现数据源的读取,使用 addSource 方法对接外部数据源时,可以使用 Flink Bundled Connector,也可以自定义 Source 。
Flink Source 的几种使用方式如下:
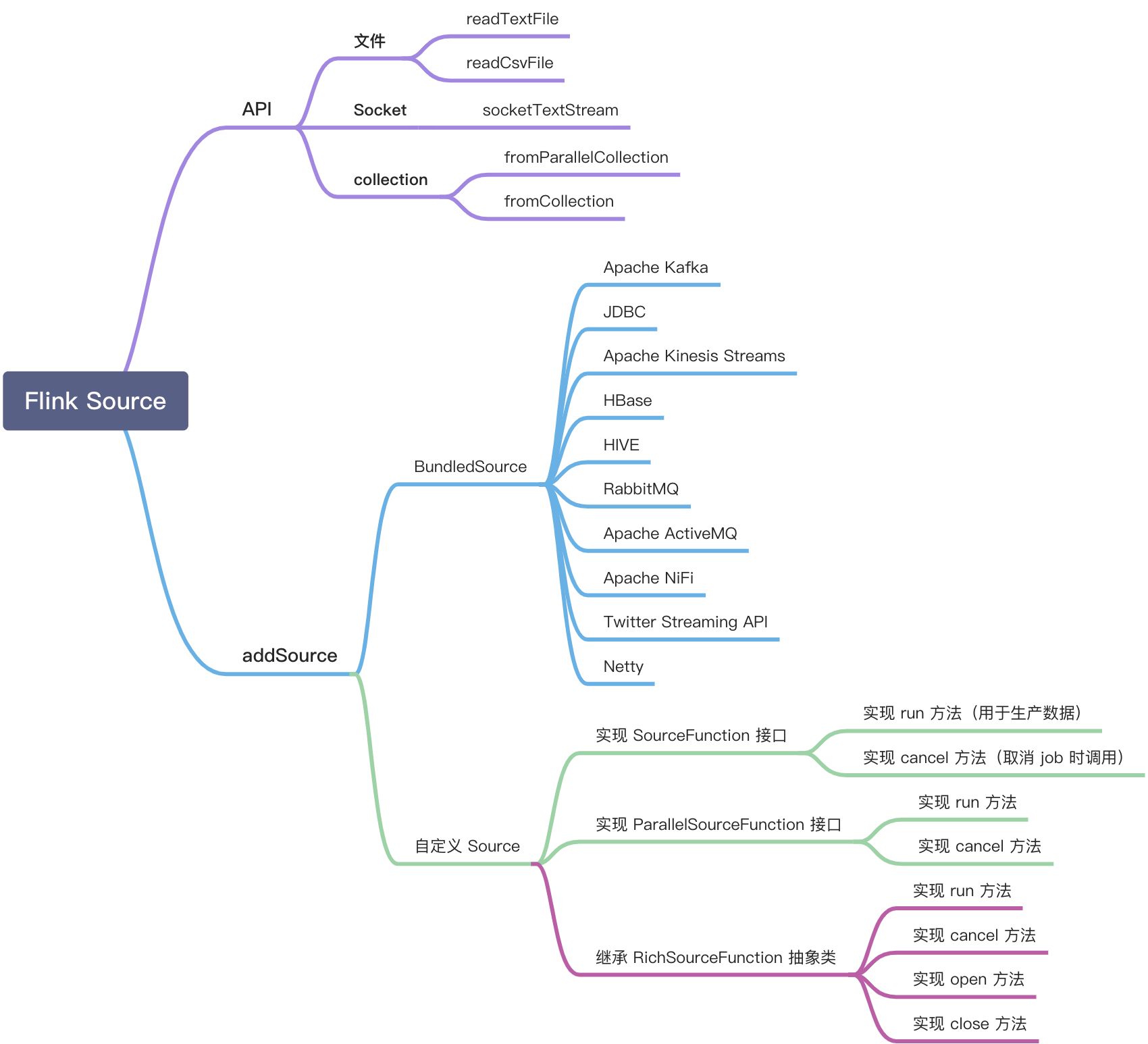
本章主要介绍如何通过自定义 Source 方式实现 Nebula Graph Source 。
1.2 自定义 Source
在 Flink 中可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 和 ExecutionEnvironment.createInput(inputFormat) 两种方式来为你的程序添加数据来源。
Flink 已经提供多个内置的 source functions ,开发者可以通过继承 RichSourceFunction来自定义非并行的 source ,通过继承 RichParallelSourceFunction 来自定义并行的 Source 。RichSourceFunction 和 RichParallelSourceFunction 是 SourceFunction 和 RichFunction 特性的结合。 其中SourceFunction 负责数据的生成, RichFunction 负责资源的管理。当然,也可以只实现 SourceFunction 接口来定义最简单的只具备获取数据功能的 dataSource 。
通常自定义一个完善的 Source 节点是通过实现 RichSourceFunction 类来完成的,该类兼具 RichFunction 和 SourceFunction 的能力,因此自定义 Flink 的 Nebula Graph Source 功能我们需要实现 RichSourceFunction 中提供的方法。
1.3 自定义 Nebula Graph Source 实现原理
Nebula Flink Connector 中实现的自定义 Nebula Graph Source 数据源提供了两种使用方式,分别是 addSource 和 createInput 方式。
Nebula Graph Source 实现类图如下:
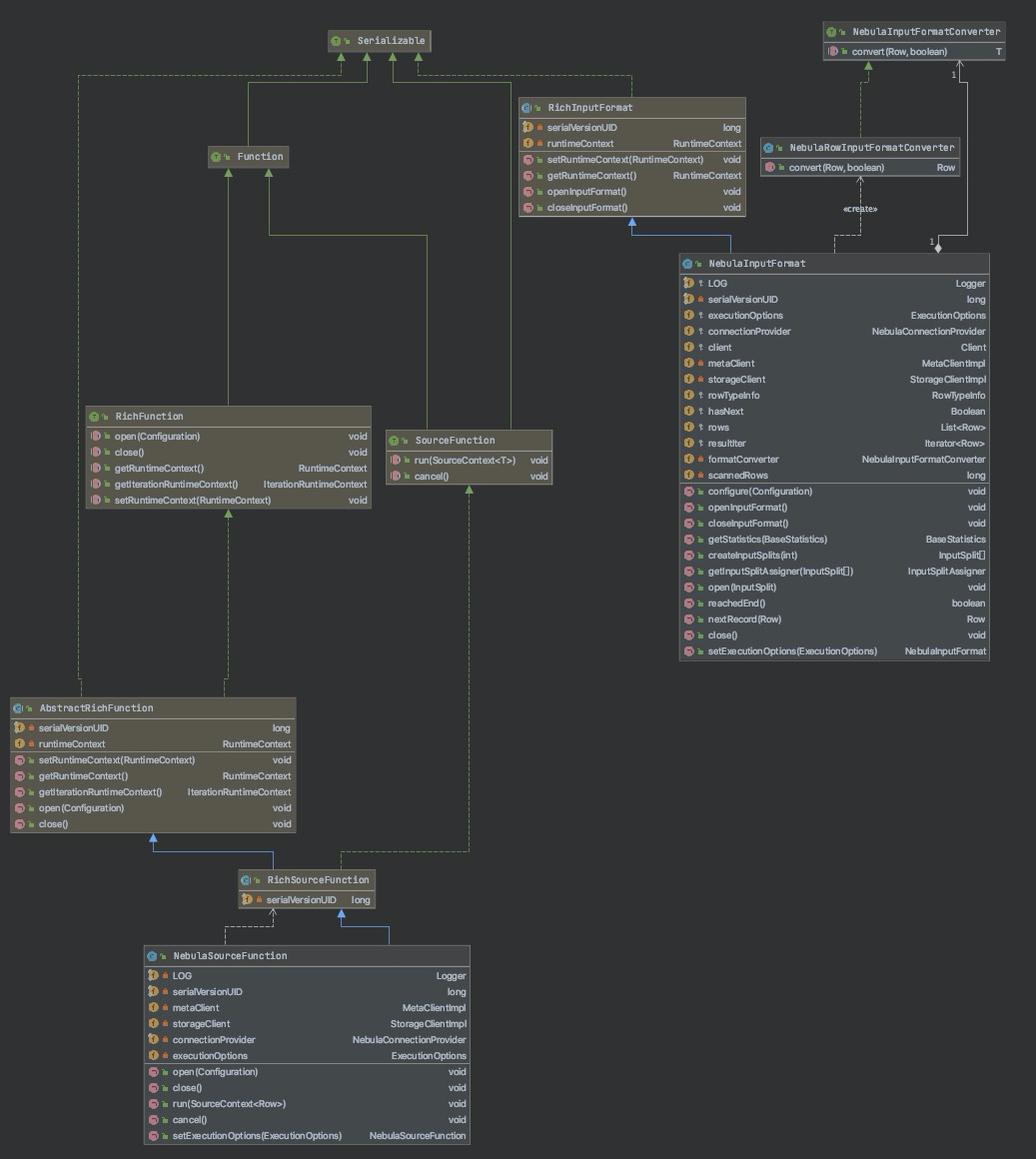
( 1 ) addSource
该方式是通过 NebulaSourceFunction 类实现的,该类继承自 RichSourceFunction 并实现了以下方法:
- open 准备 Nebula Graph 连接信息,并获取 Nebula Graph Meta 服务和 Storage 服务的连接。
- close 数据读取完成,释放资源。关闭 Nebula Graph 服务的连接。
- run 开始读取数据,并将数据填充到 sourceContext 。
- cancel 取消 Flink 作业时调用,关闭资源。
( 2 ) createInput
该方式是通过 NebulaInputFormat 类实现的,该类继承自 RichInputFormat 并实现了以下方法:
- openInputFormat 准备 inputFormat,获取连接。
- closeInputFormat 数据读取完成,释放资源,关闭 Nebula Graph 服务的连接。
- getStatistics 获取数据源的基本统计信息。
- createInputSplits 基于配置的 partition 参数创建 GenericInputSplit 。
- getInputSplitAssigner 返回输入的 split 分配器,按原始计算的顺序返回 Source 的所有 split 。
- open 开始 inputFormat 的数据读取,将读取的数据转换 Flink 的数据格式,构造迭代器。
- close 数据读取完成,打印读取日志。
- reachedEnd 是否读取完成
- nextRecord 通过迭代器获取下一条数据
通过 addSource 读取 Source 数据得到的是 Flink 的 DataStreamSource,表示 DataStream 的起点。
通过 createInput 读取数据得到的是 Flink 的 DataSource,DataSource 是一个创建新数据集的 Operator,这个 Operator 可作为进一步转换的数据集。DataSource 可以通过 withParameters 封装配置参数进行其他的操作。
1.4 自定义 Nebula Graph Source 应用实践
使用 Flink 读取 Nebula Graph 图数据时,需要构造 NebulaSourceFunction 和 NebulaOutputFormat,并通过 Flink 的 addSource 或 createInput 方法注册数据源进行 Nebula Graph 数据读取。
构造 NebulaSourceFunction 和 NebulaOutputFormat 时需要进行客户端参数的配置和执行参数的配置,说明如下:
配置项说明:
- NebulaClientOptions
- 配置 address,NebulaSource 需要配置 Nebula Graph Metad 服务的地址。
- 配置 username
- 配置 password
- VertexExecutionOptions
- 配置 GraphSpace
- 配置要读取的 tag
- 配置要读取的字段集
- 配置是否读取所有字段,默认为 false, 若配置为 true 则字段集配置无效
- 配置每次读取的数据量 limit,默认 2000
- EdgeExecutionOptions
- 配置 GraphSpace
- 配置要读取的 edge
- 配置要读取的字段集
- 配置是否读取所有字段,默认为 false, 若配置为 true 则字段集配置无效
- 配置每次读取的数据量 limit,默认 2000
// 构造 Nebula Graph 客户端连接需要的参数
NebulaClientOptions nebulaClientOptions = new NebulaClientOptions
.NebulaClientOptionsBuilder()
.setAddress("127.0.0.1:45500")
.build();
// 创建 connectionProvider
NebulaConnectionProvider metaConnectionProvider = new NebulaMetaConnectionProvider(nebulaClientOptions);
// 构造 Nebula Graph 数据读取需要的参数
List<String> cols = Arrays.asList("name", "age");
VertexExecutionOptions sourceExecutionOptions = new VertexExecutionOptions.ExecutionOptionBuilder()
.setGraphSpace("flinkSource")
.setTag(tag)
.setFields(cols)
.setLimit(100)
.builder();
// 构造 NebulaInputFormat
NebulaInputFormat inputFormat = new NebulaInputFormat(metaConnectionProvider)
.setExecutionOptions(sourceExecutionOptions);
// 方式 1 使用 createInput 方式注册 Nebula Graph 数据源
DataSource<Row> dataSource1 = ExecutionEnvironment.getExecutionEnvironment()
.createInput(inputFormat);
// 方式 2 使用 addSource 方式注册 Nebula Graph 数据源
NebulaSourceFunction sourceFunction = new NebulaSourceFunction(metaConnectionProvider)
.setExecutionOptions(sourceExecutionOptions);
DataStreamSource<Row> dataSource2 = StreamExecutionEnvironment.getExecutionEnvironment()
.addSource(sourceFunction);
Nebula Source Demo 编写完成后可以打包提交到 Flink 集群执行。
示例程序读取 Nebula Graph 的点数据并打印,该作业以 Nebula Graph 作为 Source,以 print 作为 Sink,执行结果如下:
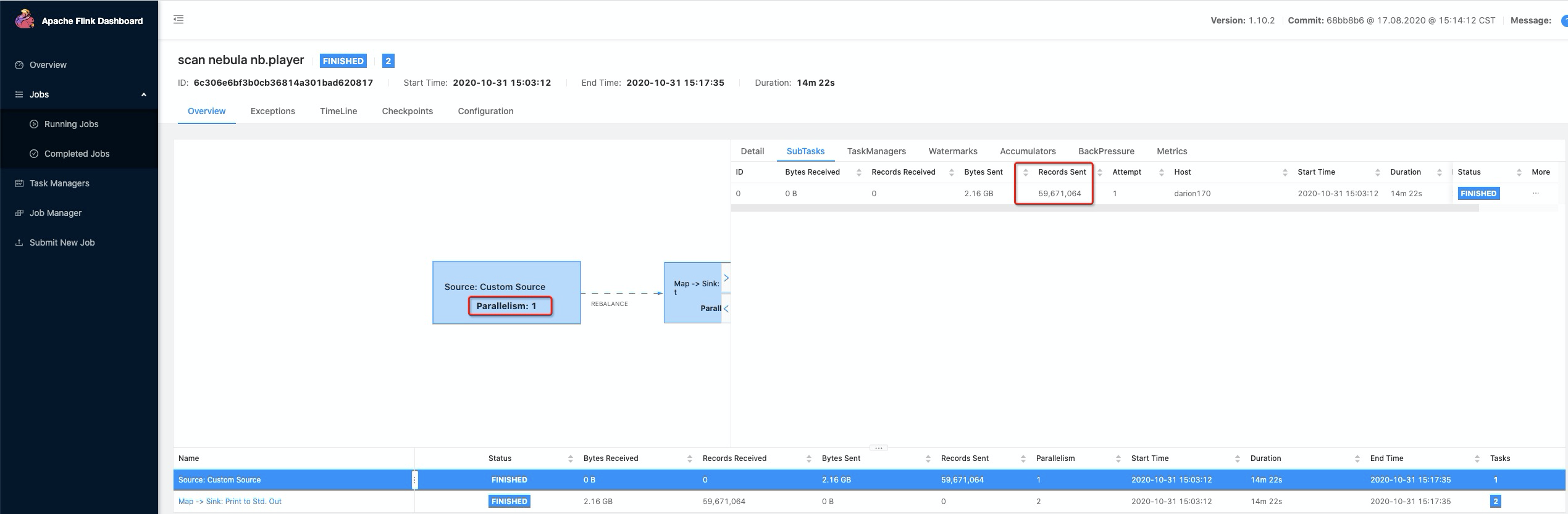
Source sent 数据为 59,671,064 条,Sink received 数据为 59,671,064 条。
二、Connector Sink
Nebula Flink Connector 中的 Sink 即 Nebula Graph 图数据库。Flink 提供了丰富的 Connector 组件允许用户自定义数据池来接收 Flink 所处理的数据流。
2.1 Sink 简介
Sink 是 Flink 处理完 Source 后数据的输出,主要负责实时计算结果的输出和持久化。比如:将数据流写入标准输出、写入文件、写入 Sockets 、写入外部系统等。
Flink 的 Sink 能力主要是通过调用数据流的 write 相关 API 和 DataStream.addSink 两种方式来实现数据流的外部存储。
类似于 Flink Connector 的 Source,Sink 也允许用户自定义来支持丰富的外部数据系统作为 Flink 的数据池。
Flink Sink 的使用方式如下:
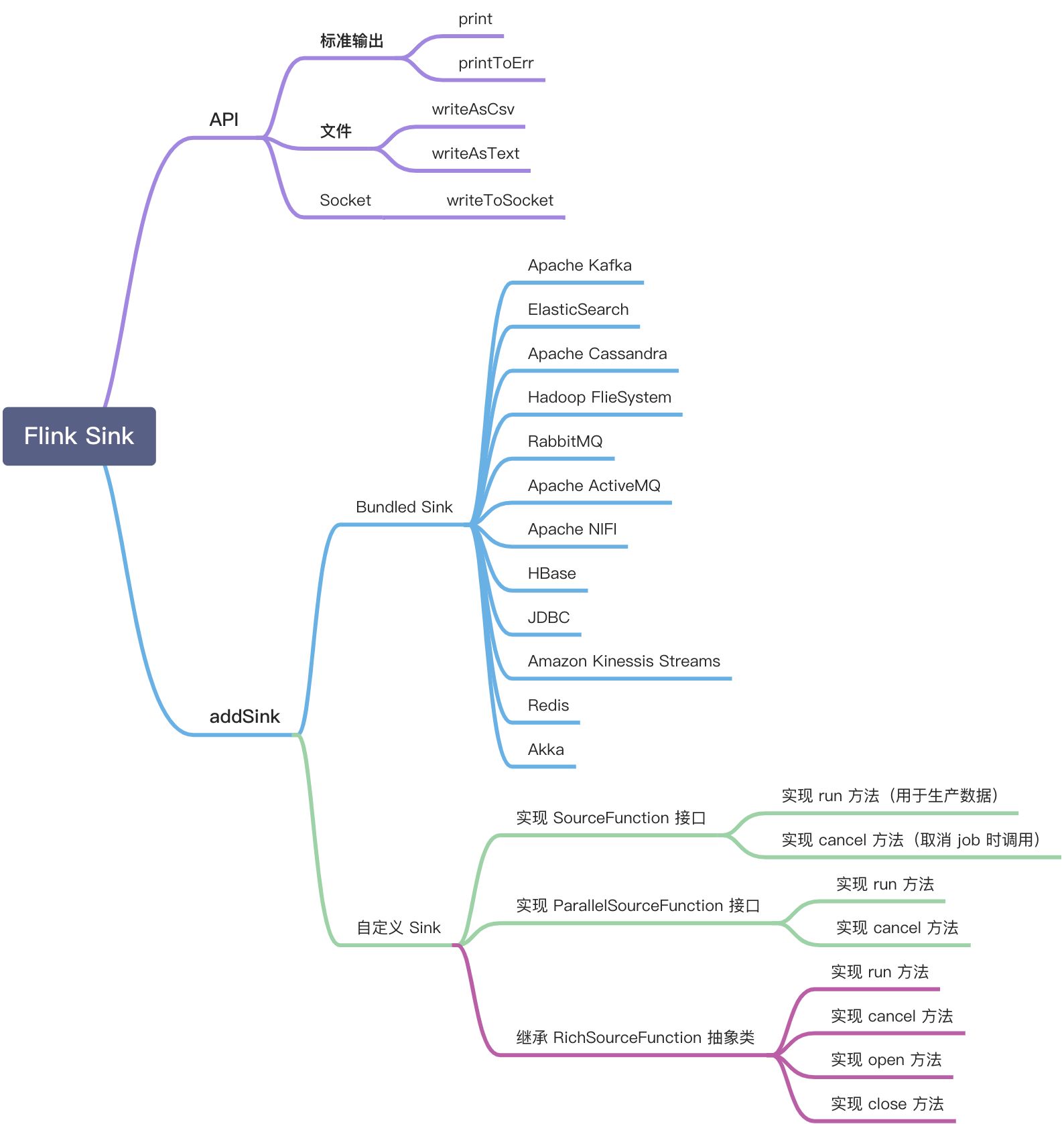
本章主要介绍如何通过自定义 Sink 的方式实现 Nebula Graph Sink 。
2.2 自定义 Sink
在 Flink 中可以使用 DataStream.addSink 和 DataStream.writeUsingOutputFormat 的方式将 Flink 数据流写入外部自定义数据池。
Flink 已经提供了若干实现好了的 Sink Functions ,也可以通过实现 SinkFunction 以及继承 RichOutputFormat 来实现自定义的 Sink 。
2.3 自定义 Nebula Graph Sink 实现原理
Nebula Flink Connector 中实现了自定义的 NebulaSinkFunction,开发者通过调用 DataSource.addSink 方法并将 NebulaSinkFunction 对象作为参数传入即可实现将 Flink 数据流写入 Nebula Graph 。
Nebula Flink Connector 使用的是 Flink 的 1.11-SNAPSHOT 版本,该版本中已经废弃了使用 writeUsingOutputFormat 方法来定义输出端的接口。
源码如下,所以请注意在使用自定义 Nebula Graph Sink 时请采用 DataStream.addSink 的方式。
/** @deprecated */
@Deprecated
@PublicEvolving
public DataStreamSink<T> writeUsingOutputFormat(OutputFormat<T> format) {
return this.addSink(new OutputFormatSinkFunction(format));
}
Nebula Graph Sink 实现类图如下:
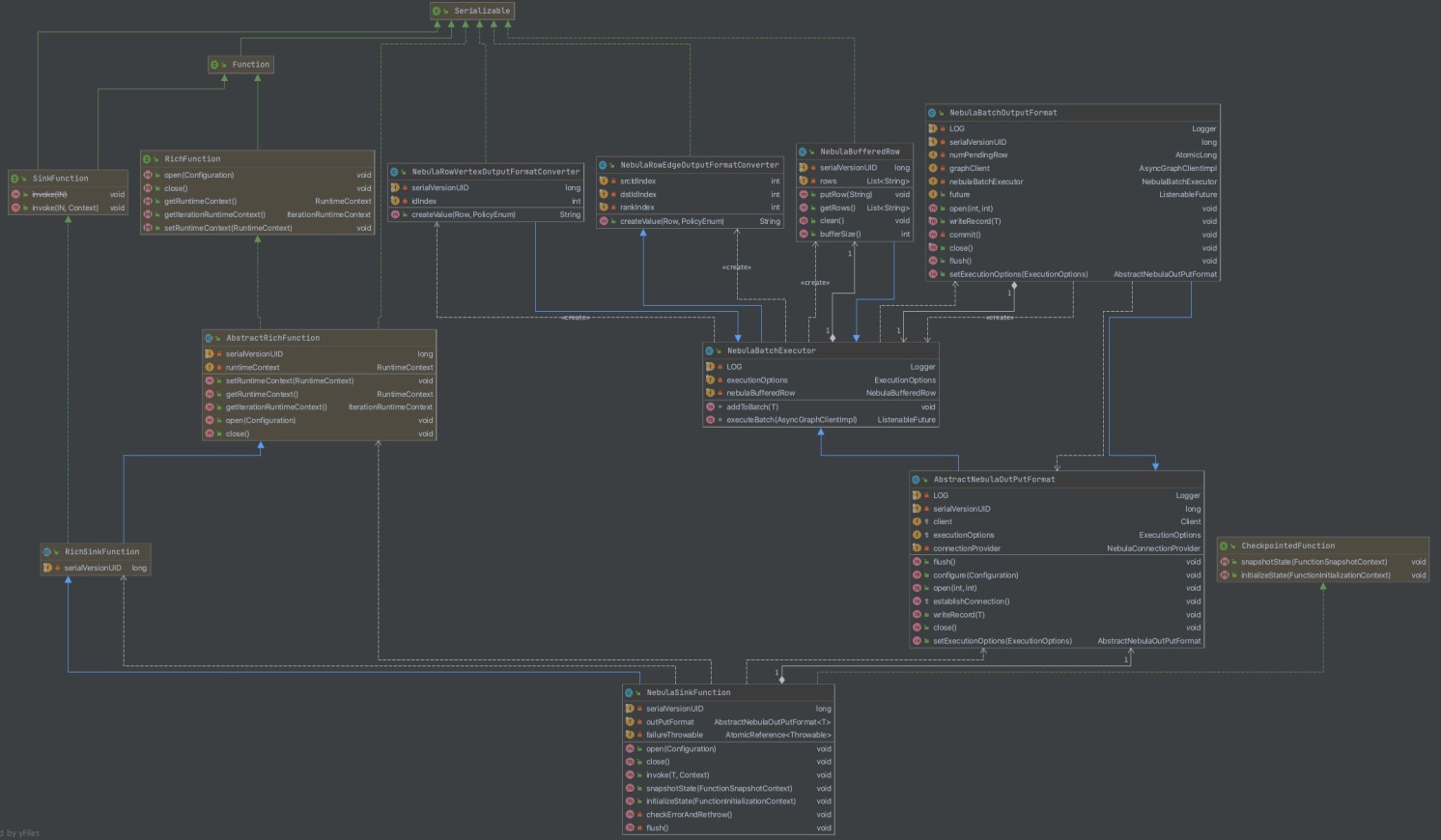
其中最重要的两个类是 NebulaSinkFunction 和 NebulaBatchOutputFormat 。
NebulaSinkFunction 继承自 AbstractRichFunction 并实现了以下方法:
- open 调用 NebulaBatchOutputFormat 的 open 方法,进行资源准备。
- close 调用 NebulaBatchOutputFormat 的 close 方法,进行资源释放。
- invoke 是 Sink 中的核心方法, 调用 NebulaBatchOutputFormat 中的 write 方法进行数据写入。
- flush 调用 NebulaBatchOutputFormat 的 flush 方法进行数据的提交。
NebulaBatchOutputFormat 继承自 AbstractNebulaOutPutFormat,AbstractNebulaOutPutFormat 继承自 RichOutputFormat,主要实现的方法有:
- open 准备图数据库 Nebula Graph 的 Graphd 服务的连接,并初始化数据写入执行器 nebulaBatchExecutor
- close 提交最后批次数据,等待最后提交的回调结果并关闭服务连接等资源。
- writeRecord 核心方法,将数据写入 nebulaBufferedRow 中,并在达到配置的批量写入 Nebula Graph 上限时提交写入。Nebula Graph Sink 的写入操作是异步的,所以需要执行回调来获取执行结果。
- flush 当 bufferRow 存在数据时,将数据提交到 Nebula Graph 中。
在 AbstractNebulaOutputFormat 中调用了 NebulaBatchExecutor 进行数据的批量管理和批量提交,并通过定义回调函数接收批量提交的结果,代码如下:
/**
* write one record to buffer
*/
@Override
public final synchronized void writeRecord(T row) throws IOException {
nebulaBatchExecutor.addToBatch(row);
if (numPendingRow.incrementAndGet() >= executionOptions.getBatch()) {
commit();
}
}
/**
* put record into buffer
*
* @param record represent vertex or edge
*/
void addToBatch(T record) {
boolean isVertex = executionOptions.getDataType().isVertex();
NebulaOutputFormatConverter converter;
if (isVertex) {
converter = new NebulaRowVertexOutputFormatConverter((VertexExecutionOptions) executionOptions);
} else {
converter = new NebulaRowEdgeOutputFormatConverter((EdgeExecutionOptions) executionOptions);
}
String value = converter.createValue(record, executionOptions.getPolicy());
if (value == null) {
return;
}
nebulaBufferedRow.putRow(value);
}
/**
* commit batch insert statements
*/
private synchronized void commit() throws IOException {
graphClient.switchSpace(executionOptions.getGraphSpace());
future = nebulaBatchExecutor.executeBatch(graphClient);
// clear waiting rows
numPendingRow.compareAndSet(executionOptions.getBatch(),0);
}
/**
* execute the insert statement
*
* @param client Asynchronous graph client
*/
ListenableFuture executeBatch(AsyncGraphClientImpl client) {
String propNames = String.join(NebulaConstant.COMMA, executionOptions.getFields());
String values = String.join(NebulaConstant.COMMA, nebulaBufferedRow.getRows());
// construct insert statement
String exec = String.format(NebulaConstant.BATCH_INSERT_TEMPLATE, executionOptions.getDataType(), executionOptions.getLabel(), propNames, values);
// execute insert statement
ListenableFuture<Optional<Integer>> execResult = client.execute(exec);
// define callback function
Futures.addCallback(execResult, new FutureCallback<Optional<Integer>>() {
@Override
public void onSuccess(Optional<Integer> integerOptional) {
if (integerOptional.isPresent()) {
if (integerOptional.get() == ErrorCode.SUCCEEDED) {
LOG.info("batch insert Succeed");
} else {
LOG.error(String.format("batch insert Error: %d",
integerOptional.get()));
}
} else {
LOG.error("batch insert Error");
}
}
@Override
public void onFailure(Throwable throwable) {
LOG.error("batch insert Error");
}
});
nebulaBufferedRow.clean();
return execResult;
}
由于 Nebula Graph Sink 的写入是批量、异步的,所以在最后业务结束 close 资源之前需要将缓存中的批量数据提交且等待写入操作的完成,以防在写入提交之前提前把 Nebula Graph Client 关闭,代码如下:
/**
* commit the batch write operator before release connection
*/
@Override
public final synchronized void close() throws IOException {
if(numPendingRow.get() > 0){
commit();
}
while(!future.isDone()){
try {
Thread.sleep(10);
} catch (InterruptedException e) {
LOG.error("sleep interrupted, ", e);
}
}
super.close();
}
2.4 自定义 Nebula Graph Sink 应用实践
Flink 将处理完成的数据 Sink 到 Nebula Graph 时,需要将 Flink 数据流进行 map 转换成 Nebula Graph Sink 可接收的数据格式。自定义 Nebula Graph Sink 的使用方式是通过 addSink 形式,将 NebulaSinkFunction 作为参数传给 addSink 方法来实现 Flink 数据流的写入。
- NebulaClientOptions
- 配置 address,NebulaSource 需要配置 Nebula Graph Graphd 服务的地址。
- 配置 username
- 配置 password
- VertexExecutionOptions
- 配置 GraphSpace
- 配置要写入的 tag
- 配置要写入的字段集
- 配置写入的点 ID 所在 Flink 数据流 Row 中的索引
- 配置批量写入 Nebula Graph 的数量,默认 2000
- EdgeExecutionOptions
- 配置 GraphSpace
- 配置要写入的 edge
- 配置要写入的字段集
- 配置写入的边 src-id 所在 Flink 数据流 Row 中的索引
- 配置写入的边 dst-id 所在 Flink 数据流 Row 中的索引
- 配置写入的边 rank 所在 Flink 数据流 Row 中的索引,不配则无 rank
- 配置批量写入 Nebula Graph 的数量,默认 2000
/// 构造 Nebula Graphd 客户端连接需要的参数
NebulaClientOptions nebulaClientOptions = new NebulaClientOptions
.NebulaClientOptionsBuilder()
.setAddress("127.0.0.1:3699")
.build();
NebulaConnectionProvider graphConnectionProvider = new NebulaGraphConnectionProvider(nebulaClientOptions);
// 构造 Nebula Graph 写入操作参数
List<String> cols = Arrays.asList("name", "age")
ExecutionOptions sinkExecutionOptions = new VertexExecutionOptions.ExecutionOptionBuilder()
.setGraphSpace("flinkSink")
.setTag(tag)
.setFields(cols)
.setIdIndex(0)
.setBatch(20)
.builder();
// 写入 Nebula Graph
dataSource.addSink(nebulaSinkFunction);
Nebula Graph Sink 的 Demo 程序以 Nebula Graph 的 space:flinkSource 作为 Source 读取数据,进行 map 类型转换后 Sink 入 Nebula Graph 的 space:flinkSink,对应的应用场景为将 Nebula Graph 中一个 space 的数据流入另一个 space 中。
三、Catalog
Flink 1.11.0 之前,用户如果依赖 Flink 的 Source/Sink 读写外部数据源时,必须要手动读取对应数据系统的 Schema 。比如,要读写 Nebula Graph,则必须先保证明确地知晓在 Nebula Graph 中的 Schema 信息。但是这样会有一个问题,当 Nebula Graph 中的 Schema 发生变化时,也需要手动更新对应的 Flink 任务以保持类型匹配,任何不匹配都会造成运行时报错使作业失败。这个操作冗余且繁琐,体验极差。
1.11.0 版本后,用户使用 Flink Connector 时可以自动获取表的 Schema 。可以在不了解外部系统数据 Schema 的情况下进行数据匹配。
目前 Nebula Flink Connector 中已支持数据的读写,要实现 Schema 的匹配则需要为 Flink Connector 实现 Catalog 的管理。但为了确保 Nebula Graph 中数据的安全性,Nebula Flink Connector 只支持 Catalog 的读操作,不允许进行 Catalog 的修改和写入。
访问 Nebula Graph 指定类型的数据时,完整路径应该是以下格式:<graphSpace>.<VERTEX.tag> 或者 <graphSpace>.<EDGE.edge>
具体使用方式如下:
String catalogName = "testCatalog";
String defaultSpace = "flinkSink";
String username = "root";
String password = "nebula";
String address = "127.0.0.1:45500";
String table = "VERTEX.player"
// define Nebula catalog
Catalog catalog = NebulaCatalogUtils.createNebulaCatalog(catalogName,defaultSpace, address, username, password);
// define Flink table environment
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
tEnv = StreamTableEnvironment.create(bsEnv);
// register customed nebula catalog
tEnv.registerCatalog(catalogName, catalog);
// use customed nebula catalog
tEnv.useCatalog(catalogName);
// show graph spaces of Nebula Graph
String[] spaces = tEnv.listDatabases();
// show tags and edges of Nebula Graph
tEnv.useDatabase(defaultSpace);
String[] tables = tEnv.listTables();
// check tag player exist in defaultSpace
ObjectPath path = new ObjectPath(defaultSpace, table);
assert catalog.tableExists(path) == true
// get nebula tag schema
CatalogBaseTable table = catalog.getTable(new ObjectPath(defaultSpace, table));
table.getSchema();
Nebula Flink Connector 支持的其他 Catalog 接口请查看 GitHub 代码 NebulaCatalog.java 。
四、Exactly-once
Flink Connector 的 Exactly-once 是指 Flink 借助于 checkpoint 机制保证每个输入事件只对最终结果影响一次,在数据处理过程中即使出现故障,也不会存在数据重复和丢失的情况。
为了提供端到端的 Exactly-once 语义,Flink 的外部数据系统也必须提供提交或回滚的方法,然后通过 Flink 的 checkpoint 机制协调。Flink 提供了实现端到端的 Exactly-once 的抽象,即实现二阶段提交的抽象类 TwoPhaseCommitSinkFunction 。
想为数据输出端实现 Exactly-once,则需要实现四个函数:
- beginTransaction 在事务开始前,在目标文件系统的临时目录创建一个临时文件,随后可以在数据处理时将数据写入此文件。
- preCommit 在预提交阶段,关闭文件不再写入。为下一个 checkpoint 的任何后续文件写入启动一个新事务。
- commit 在提交阶段,将预提交阶段的文件原子地移动到真正的目标目录。二阶段提交过程会增加输出数据可见性的延迟。
- abort 在终止阶段,删除临时文件。
根据上述函数可看出,Flink 的二阶段提交对外部数据源有要求,即 Source 数据源必须具备重发功能,Sink 数据池必须支持事务提交和幂等写。
Nebula Graph v1.1.0 虽然不支持事务,但其写入操作是幂等的,即同一条数据的多次写入结果是一致的。因此可以通过 checkpoint 机制实现 Nebula Flink Connector 的 At-least-Once 机制,根据多次写入的幂等性可以间接实现 Sink 的 Exactly-once 。
要使用 Nebula Graph Sink 的容错性,请确保在 Flink 的执行环境中开启了 checkpoint 配置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(10000) // checkpoint every 10000 msecs
.getCheckpointConfig()
.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
Reference
- Nebula Source Demo [testNebulaSource]:https://github.com/vesoft-inc/nebula-java/blob/master/examples/src/main/java/org/apache/flink/FlinkDemo.java
- Nebula Sink Demo [testSourceSink]:https://github.com/vesoft-inc/nebula-java/blob/master/examples/src/main/java/org/apache/flink/FlinkDemo.java
- Apache Flink 源码:https://github.com/apache/flink
- ApacheFlink 零基础入门:https://www.infoq.cn/theme/28
- Flink 文档:https://flink.apache.org/flink-architecture.html
- Flink 实践文档:https://ci.apache.org/projects/flink/flink-docs-release-1.12/
- flink-connector-jdbc 源码:https://github.com/apache/flink/tree/master/flink-connectors/flink-connector-jdbc
- Flink JDBC Catalog 详解:https://cloud.tencent.com/developer/article/1697913
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~
{kind=link}
目前尚无回复